

Verdens mest populære relasjonsdatabase kan mer enn å ta vare på tabellene dine.

Dette er første artikkel i en artikkelserie om PostgreSQL. Målet med serien er å synliggjøre bruksområder og muligheter du kanskje ikke var klar over at din favorittdatabase hadde, og hjelpe deg i gang med praktiske tips og triks.
PostgreSQL er verdens mest populære relasjonsdatabase , med klar margin ned til konkurrentene sine. Det er samtidig databaseteknologien som flest er fornøyd med . Hvorfor det? Hva er det som gjør PostgreSQL bedre enn sine konkurrenter? Er det på grunn av hastighet og nyttig ekstra-funksjonalitet som gjør SQL-spørringene dine litt enklere å resonnere rundt?
Det kan godt hende. Det er hvertfall gode argumenter for hvorfor en burde velge PostgreSQL om du trenger et sted å lagre relasjonell data. Et annet mindre kjent argument er at PostgreSQL kan så mye mer enn å være kun en relasjonsdatabase. Databasen kommer med funksjonalitet for å bygge egne utvidelser ( extension s), og har over tid fått et stort økosystem rundt utvidelser som muliggjør å bruke PostgreSQL til oppgaver du tidligere trengte andre verktøy til.

Et eksempel på dette er den populære utvidelsen pgvector , som gir deg muligheten til å gjøre vektorsøk og bruke vektoroperasjoner på dataen din. Denne utvidelsen var tidligere kun brukt av et knippe utviklere, men da ChatGPT ble lansert i 2022 og alle plutselig skulle gjøre RAG (Retrieval Augmented Generation, en metode for å hente ut dokumenter basert på innholdet i dem og gi det som kontekst til språkmodeller for å generere bedre svar) skjøt populariteten i været over natten. Plutselig skulle alle lage sin egen chatbot som svarte på spørsmål om innhold i dokumentene sine, eller prøve å implementere en LLM-basert chatbot for kundeservice basert på rutiner og dokumenter i bedriften.
For å få til RAG trengs det som kalles semantisk søk , kort forklart et søk etter tekst som innholdsmessig likner på annen tekst. Et konkret eksempel kan være å lete etter svar på spørsmålet “Hvor mye koster bussbilletten?”. Et semantisk søk vil da returnere dokumenter eller paragrafer du har lagret i databasen din med tekst som inneholder informasjon om billettpriser. Selv om spørsmålet ikke spesifikt inneholder ordet “pris”, er meningen i innholdet det samme: det handler om priser på billetter.
Under overflaten fungerer semantisk søk ved å sammenlikne vektorer (representert av en datamaskin som en liste med tall) som representerer meningsinnholdet i en tekst. Teorien er at vektorer som er “like” hverandre inneholder liknende meningsinnhold, så ved å gjøre om spørringen sin til en vektor og søke etter de “likeste” vektor-representasjonen av dokumentene sine så vil en få tak i de dokumentene som mest sannsynlig kan svare på spørsmålet ditt.
Men hvordan kan en avgjøre om to vektorer er “like”? Det er her pgvector kommer til unnsetning. En extension kan gi PostgreSQL nye datatyper, operatorer, indekstyper og mye mer, og pgvector gir oss datatypen VECTOR, operatorer for å sammenlikne hvor like to vektorer er og indekser som gjør søk i vektor-kolonner raskt. Som nevnt er en VECTOR i teorien kun en liste tall med en gitt lengde (kalt antall dimensjoner), og kan etter installasjon av pgvector opprettes på denne måten:
CREATE TABLE document (
id BIGSERIAL PRIMARY KEY,
content TEXT NOT NULL,
embedding VECTOR(512) NOT NULL
)
Dette vil opprette en kolonne kalt embedding for vektorer med 512 dimensjoner. Hvorfor akkurat 512 dimensjoner? Dette må velges utifra modellen en bruker til å generere vektorene fra tekstinnhold. ChatGPT sine modeller bruker ofte 3072 dimensjoner, mens andre modeller kan ha andre lengder.
For å sammenlikne vektorene som lagres i vektor-kolonnen vår, trenger vi noen operatorer. pgvector kommer med flere alternativer, hvor de tre vanligste er cosinus-distanse (<=>), L2-distanse (<->) og dottprodukt (<#>), som alle har hver sin algoritme for å måle hvor “like” to vektorer er.
Cosinus-distanse fungerer ved å plassere starten på vektorene i samme punkt og måle vinkelen mellom dem. Dette resulterer i et tall mellom -1 og 1, hvor -1 tilsvarer to vektorer som peker i motsatt retning av hverandre, og 1 tilsvarer to vektorer som peker samme retning. Om to vektorer peker samme vei vil vi si at de er “like” hverandre. For at denne målemetoden skal gi mening er det viktig at vektorene er like lange, dvs at summen av alle tallene i hver vektoren er lik. Dette kalles normalisering, og lengden på vektoren settes som regel til 1.
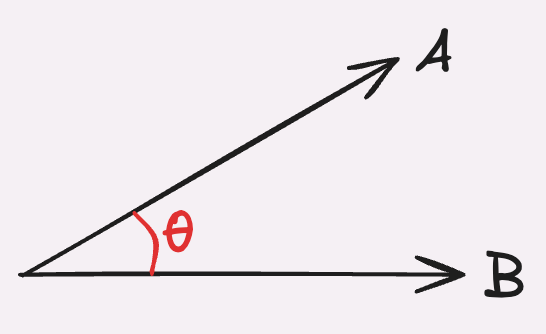
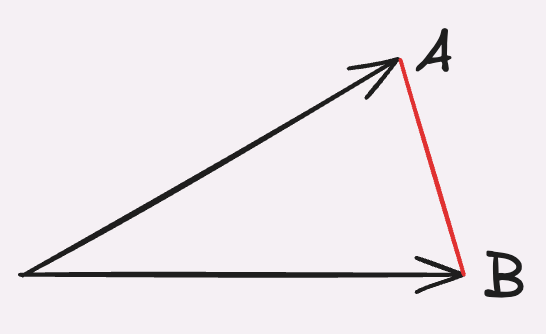
L2-distanse fungerer ved å plassere vektorene i samme punkt og deretter måle avstanden mellom punktene hvor vektorene peker til. Her vil et lavt tall bety at vektorene er like hverandre ettersom vektorene peker på cirka samme punkt, mens et høyt tall betyr at vektorene peker langt fra hverandre og at de dermed er ulike.
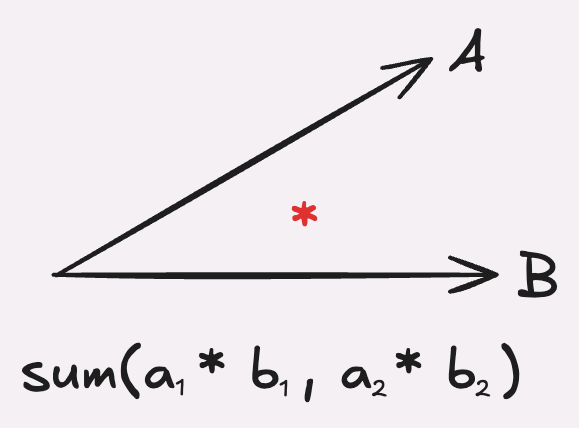
Dottprodukt er den samme algoritmen som en lærer i realfagsmatematikk på videregående, hvor en multipliserer sammen hvert tilsvarende element i vektorene og summerer det sammen. Resultatet blir et tall, hvor et høyt positivt tall betyr at vektorene peker i samme retning og dermed er like hverandre, mens et stort negativt tall vil si at de peker i forskjellige retning og dermed er ulike.
Av disse tre operatorene er det cosinus-distanse som er den vanligste å bruke. Operatoren som pgvector definerer for dette er ““, og en spørring vil dermed se slik ut:
SELECT content
FROM document
ORDER BY embedding '[3,1,2, …]'
LIMIT 10
Dette vil gi deg de ti dokumentene som er semantisk likest vektoren [3, 1, 2, …] ved å bruke cosinus-distanse for å måle likheten mellom vektorene i databasen.
Med disse to grepene har vi nå all funksjonaliteten en trenger for å muliggjøre vektorsøk i PostgreSQL, men det er et viktig punkt vi ikke har dekket enda: Hva skjer når dataene våre vokser og det blir millioner av dokumenter (og derav vektorer) i databasen vår? pgvector vil fortsatt kunne gjøre semantisk søk, men å gjøre det på samtlige vektorer i databasen hver gang kommer til å ta lang tid. Heldigvis kommer pgvector innebygd med en løsning for dette også, ved å tilby to indekstyper som kan brukes til å redusere antallet vektorer vi trenger å regne ut cosinus-distansen til.
Disse indeksene heter HNSW (Hierarchical Navigable Small World) og IVFFlat (Inverted File with Flat Compression), og kommer begge med et par trade-offs mellom presisjon, hurtighet og minnebruk. HNSW gir deg raskere søk med høyere minnebruk og noe tap i presisjon, mens IVFFlat gir deg litt tregere søk, men med lavere minnebruk og økt presisjon. Hvilken type indeks du bør velge avhenger av kravene til ressursbruk og hvor viktig det er å gi helt nøyaktige svar i din applikasjon.
Med den siste brikken i puslespillet på plass har vi nå alle byggeklossene vi trenger for å kunne skalere vektorsøk og ta det i bruk i en produksjons-setting. Støtte for pgvector er tilgjengelig i de fleste managed services for PostgreSQL hos de store skylevarandører som AWS, Azure, Google Cloud og ScaleWay. Om du administrerer din egen databaseserver er det ikke verre enn å installere det med pgxman eller å laste ned koden direkte fra Github . Å komme i gang er med andre ord lekende lett, så om du ønsker å bruke RAG eller semantisk innholdsøk i ditt neste prosjekt burde du sterkt vurdere PostgreSQL som din vektordatabase.

Vemund er en senior fullstackutvikler med erfaring fra både knøttsmå startups i Silicon Valley og større bedrifter som Finn.no og Tet Digital i Norge. Han trives best i krysningspunktet mellom komplekse utviklerutfordringer som krever tett oppfølging mellom backend, frontend og infrastruktur og AI-enablement i enterprise-settinger som gir muligheter for kontinuerlig læring og vekst.


