

I de forrige innleggene har vi etablert hvordan agentiske arbeidsflyter skiller seg fra tradisjonelle chatbots, hvordan MCP kobler agenter til omverdenen, og hvordan CLI-agenter gir oss kraftige verktøy i terminalen. Men vi har ennå ikke besvart et fundamentalt spørsmål: Hvordan tenker egentlig en agent?

Ved veldig naivt bruk av AI-verktøy i dag opplever mange at modellen "skyter fra hofta" – den gir et svar uten å vise arbeidet sitt, og resultatet blir ofte upresist eller direkte feil. Problemet er at LLM-er uten struktur mangler en mekanisme for å bryte ned komplekse oppgaver. De prøver å løse alt i ett steg.
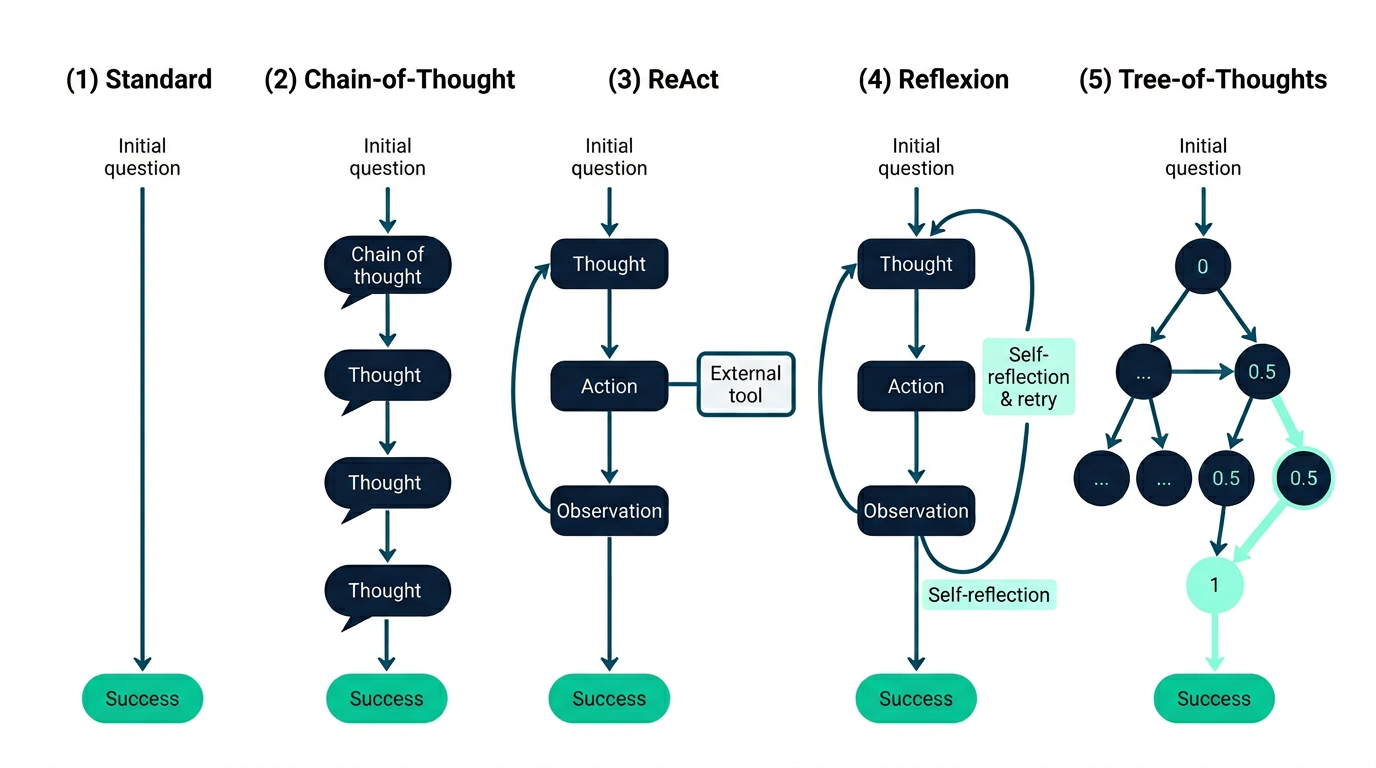
Løsningen heter ReAct – et mønster som kombinerer Reasoning (resonnering) og Acting (handling) i en iterativ syklus. Dette er fundamentet for hvordan moderne agenter planlegger og utfører arbeid, og det er et viktig mønster å beherske for å forstå resten av denne bloggserien.
Du har sannsynligvis allerede sett ReAct i aksjon uten å vite det. Når Claude Code leser en fil i terminalen din, resonnerer over en bug mens den tenker, og deretter redigerer koden – det er en ReAct-loop. Når ChatGPT søker på nettet, leser resultatene, og formulerer et svar basert på det den fant – det er også ReAct. Mønsteret er overalt i moderne AI-verktøy.
ReAct ble introdusert av Yao et al. i 2022, og ideen er elegant i sin enkelhet: La modellen tenke høyt før hver handling. I stedet for å generere et endelig svar direkte, alternerer agenten mellom tre faser:
Denne syklusen gjentas til agenten har nok informasjon til å gi et endelig svar, eller utilstrekkelig informasjon og må be brukeren om mer kontekst før den kan fortsette.
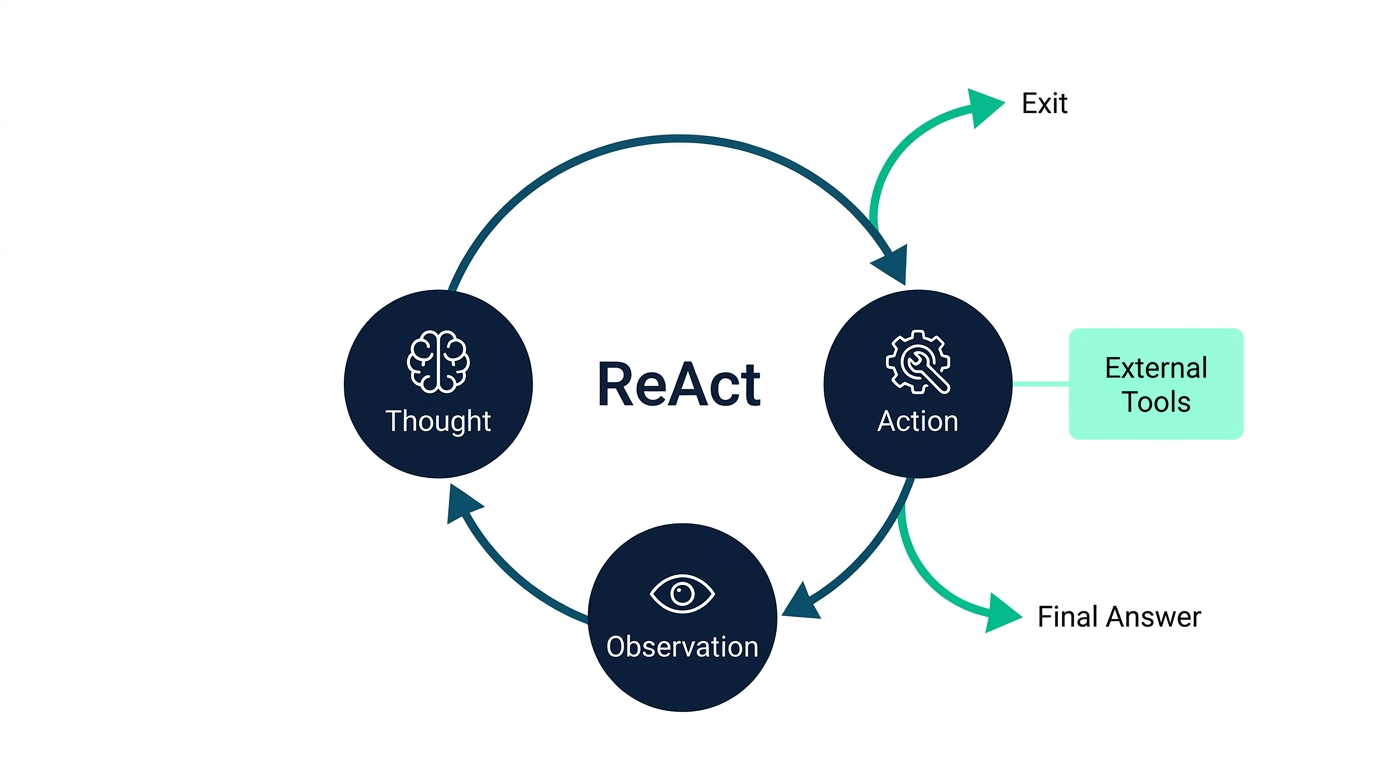
Hvorfor fungerer dette bedre enn ren resonnering? Forskjellen ligger i tilbakemeldingssløyfen. Chain-of-Thought (CoT), en annen teknikk, lar modellen tenke steg-for-steg, men den kan bare resonnere basert på det den allerede "vet". Uten tilgang til verktøy risikerer den å hallusinere fakta. ReAct løser dette (så fremt den har tilgang på gode verktøy) ved å la modellen sjekke antakelsene sine mot virkeligheten gjennom handlinger.
Jeg vil dele en erfaring fra et prosjekt jeg jobber med, fordi det illustrerer nøyaktig hvorfor ReAct-mønsteret er så viktig å forstå.
Vi hadde bygget en chatbot med LangGraph som virket imponerende på papiret: RAG-basert kontekstinnhenting, intensjonsklassifisering, reranking av resultater, og forretningskritiske guardrails. Den hentet relevant kontekst, genererte svar, og strømmet dem tilbake til klienten. I mitt hode hadde jeg laget en agentisk chatbot.
Men det hadde jeg ikke.
Det jeg hadde bygget var en sofistikert pipeline – en lineær flyt fra input til output. Brukerens spørsmål gikk inn, kontekst ble hentet, et svar ble generert, ferdig. Hvis svaret var utilstrekkelig eller basert på feil kontekst, var det ingen mekanisme for å prøve igjen med en annen strategi. Chatboten kunne ikke resonnere om hva den manglet.
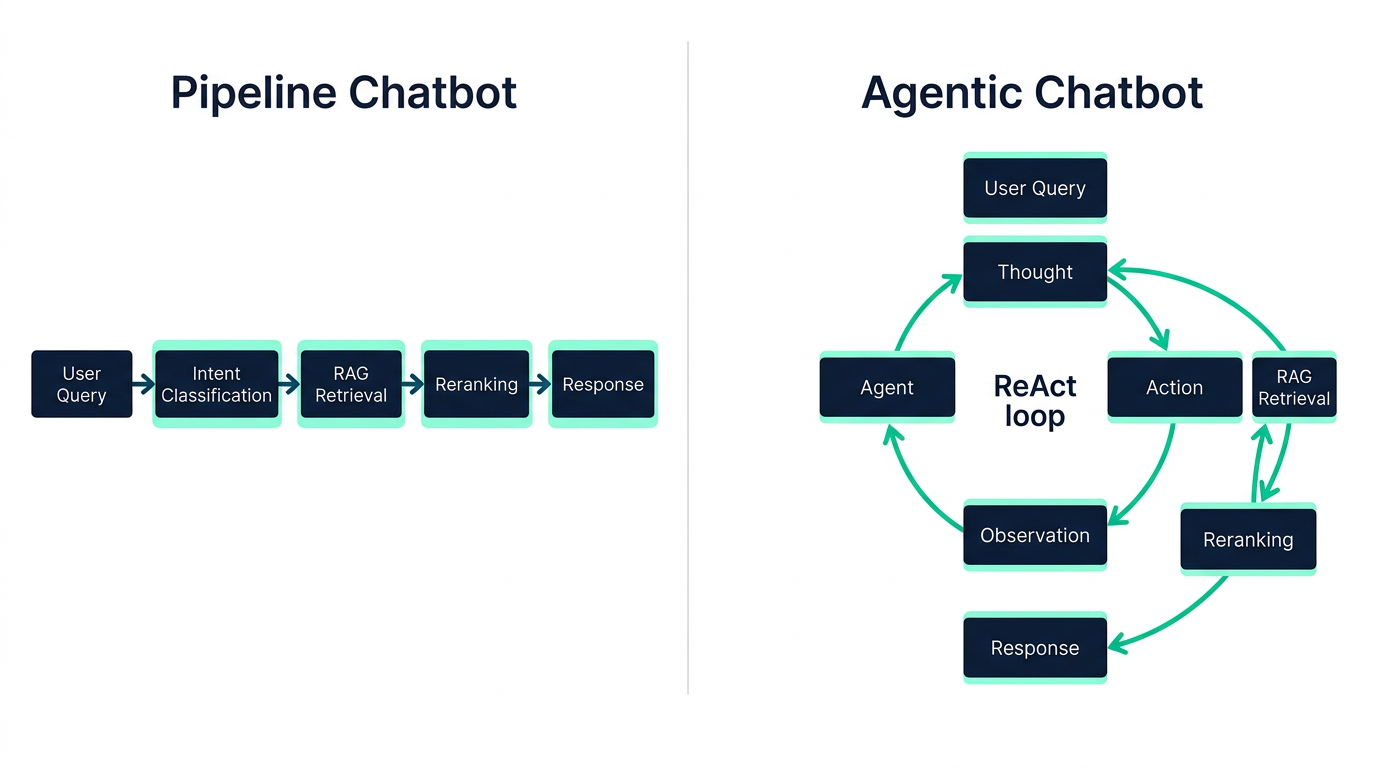
Det som manglet var selve ReAct-loopen – den iterative syklusen der agenten resonnerer, velger et verktøy, observerer resultatet, og bestemmer neste steg. Og like viktig: granulære, komponerbare verktøy som agenten faktisk kan bruke til å utforske og handle.
# Granulære, komponerbare verktøy
@tool
def get_customer_by_id(customer_id: str) -> str:
"""Hent kundeinformasjon basert på kunde-ID."""
...
@tool
def search_orders(query: str, status: str | None = None) -> str:
"""Søk i ordrer med valgfri statusfiltrering."""
...
@tool
def create_support_ticket(customer_id: str, description: str) -> str:
"""Opprett en ny support-sak for en kunde."""
...
@tool
def update_order_status(order_id: str, new_status: str) -> str:
"""Oppdater status på en eksisterende ordre."""
...
Da vi koblet en create_react_agent med disse verktøyene inn i den eksisterende LangGraph-grafen – som allerede hadde guardrails, intensjonsklassifisering, og retrieval – skjedde noe fundamentalt annerledes. Nå hadde vi en chatbot som kunne resonnere: "Brukeren spør om X, la meg slå opp kunde-ID-en først, deretter søke i Y, og hvis det er et problem, opprette en Z." Flere verktøykall, drevet av resonnering, ikke en strengt definert pipeline.
Det er dette skillet jeg vil at du som leser skal forstå. En chatbot med RAG og fine pipelines er ikke automatisk agentisk. Den blir agentisk når den har en ReAct-loop som
lar den velge hva den skal gjøre basert på hva den observerer.
La oss se hvordan dette ser ut i kode. Med LangGraph blir implementeringen superenkel. Her er et komplett eksempel:
from langgraph.prebuilt import create_react_agent
from langchain_openai import ChatOpenAI
from langchain_core.tools import tool
@tool
def search_codebase(query: str) -> str:
"""Search the codebase for relevant files."""
# Implementation
return f"Found 3 files matching '{query}'"
@tool
def read_file(path: str) -> str:
"""Read contents of a file."""
return Path(path).read_text()
# Create the ReAct agent
agent = create_react_agent(
model=ChatOpenAI(model="gpt-4"),
tools=[search_codebase, read_file],
)
# Run it
result = agent.invoke({
"messages": [("user", "Find the auth bug in our codebase")]
})
Det viktige her er @tool-dekoratoren som gir modellen klare beskrivelser av hva hvert verktøy gjør. Jo bedre dokumentert verktøyene er, jo mer presise blir agentens beslutninger.
ReAct fungerer utmerket for oppgaver som kan løses iterativt, men noen ganger trenger vi mer struktur. Her kommer planning patterns inn i bildet.
I stedet for å la agenten improvisere hvert steg, kan vi separere planlegging fra utførelse:
class PlanningAgent:
def plan(self, goal: str) -> list[Task]:
"""Create a todo list for achieving the goal."""
return self.llm.generate_plan(goal)
def execute(self, tasks: list[Task]):
"""Execute tasks, replanning if needed."""
for task in tasks:
result = self.execute_task(task)
if result.requires_replanning:
tasks = self.replan(tasks, result)
Fordelen med dette mønsteret er naturlige kontrollpunkter. Etter planleggingsfasen kan et menneske godkjenne planen før utførelse starter; en form for human-in-the-loop som gir et nivå av trygghet før utførelse.
I den virkelige verden går sjelden alt etter planen. Moderne agenter må derfor kunne justere kursen underveis. Hvis et verktøykall feiler eller returnerer uventet data, bør agenten kunne oppdatere sin plan basert på den nye informasjonen.
LangGraph tilbyr flere arkitekturer for dette, inkludert ReWOO (Reasoning Without Observations) som lar agenten lage en komplett plan med variabler som fylles inn etter hvert som stegene utføres.
En naturlig utvidelse av ReAct er Reflexion, introdusert av Shinn et al. i 2023. Der ReAct lar agenten tenke og handle, lar Reflexion agenten evaluere sine egne forsøk og eksplisitt reflektere over hva som gikk galt.
Arkitekturen består av tre komponenter: en Actor som genererer handlinger, en Evaluator som scorer resultatet, og en Self-Reflection-modul som produserer verbal feedback. Denne feedbacken lagres i et episodisk minne og brukes som kontekst i neste forsøk.
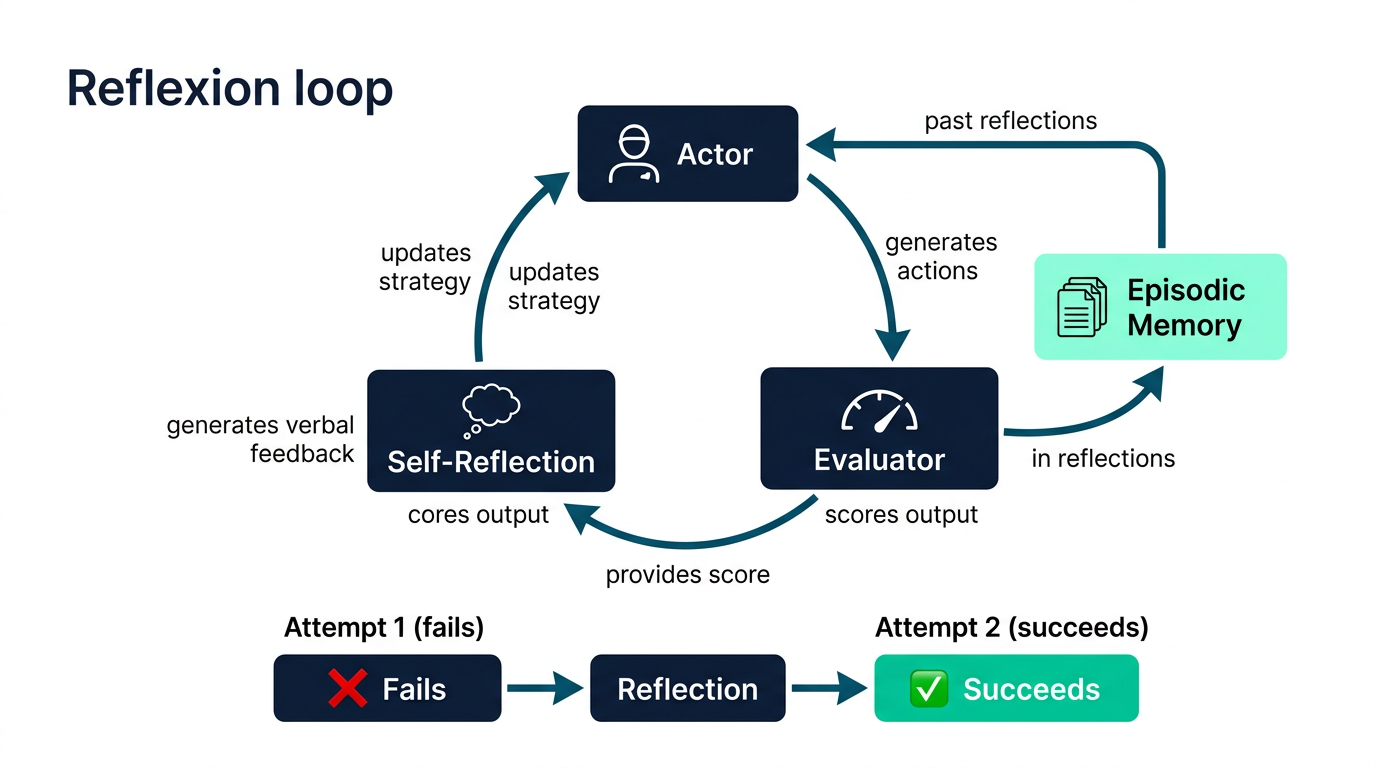
I praksis er dette mønsteret du gjenkjenner når en CI-pipeline feiler og agenten din leser feilmeldingen, resonnerer over årsaken, og prøver en annen tilnærming. Det er ikke bare retry – det er retry med selvrefleksjon.
Når bør du bruke hva? Her er en rask oversikt:

Tree-of-Thoughts er verdt å nevne for oppgaver der lineær tenkning ikke holder. Ved å utforske flere resonneringsstier parallelt og evaluere dem, kan modellen oppnå bedre resultater på kreative oppgaver, men til en høyere kostnad i API-kall.
Når du implementerer ReAct-baserte agenter, pass på disse fellene:
max_iterations. En agent kan bli stuck i en loop der den gjentar samme handling.
Ved å la modellen tenke høyt, handle basert på resonnering, og justere basert på observasjoner, får vi systemer som er mer transparente, mer pålitelige og betydelig mer kapable enn enkle prompt-baserte løsninger.
Den viktigste lærdommen er at struktur slår improvisasjon. Enten du bruker ren ReAct, Plan-and-Execute, eller en hybrid tilnærming, handler det om å gi agenten et rammeverk for å bryte ned kompleksitet.

Magnus bygger AI i Capra, nå på Gjensidiges «Hei, huset!». Han er opptatt av AI som fungerer i praksis og av å rigge tverrfaglige team for en AI-first arbeidsform. Det skriver han om og holder foredrag om.


