

Tenk på hva du har tilgjengelig i Claude Code. Filsystemverktøy som leser, skriver og søker i kode. Planlegging som bryter ned komplekse oppgaver i håndterbare steg. Oppgavesporing som holder oversikt over fremdriften. Persistent minne som husker kontekst på tvers av samtaler. Subagenter som kan delegeres spesialiserte oppgaver. Automatisk kontekststyring som forhindrer at vinduet flyter over.
De fleste utviklere har kjent denne kraften. Men har du gitt mye tanke til kompleksiteten det innebærer å faktisk implementere disse egenskapene for din egen agent, den som kjører i din applikasjon?
Si at du bygger en domenespesifikk agent for bank, forsikring eller helse. Du forventer at denne digitale medarbeideren skal være minst like kapabel som om du kastet det samme domeneproblemet til et fullverdig Claude Code-oppsett. Men å bygge alt det fra scratch? Det krever en enorm mengde kode, og det er vanskelig å få til helt riktig.
Her kommer deepagents inn. Inspirert av applikasjoner som Claude Code, Deep Research og Manus, gir dette open source-biblioteket deg "batteries included" for agenter som takler komplekse, flerstegs oppgaver.
For å forstå hva deepagents er, hjelper det med en analogi.
Tenk på en fjellklatrer. Klatreren selv er sterk og kompetent (det er modellen din, GPT, Claude, Gemini). Men styrke alene får deg ikke opp fjellveggen. Du trenger en sele: tau, karabinere, sikringsenheter, kritt-pose, og en ryggsekk med proviant. Selen gjør ikke klatreren sterkere. Den gjør klatreren brukbar i krevende terreng.
Det er akkurat det en agent harness gjør for en språkmodell. Når frontiermodellene fra de store labene allerede er ekstremt kapable, er det ikke modellen som er differensiatoren i agentiske arbeidsflyter. Det er selen rundt den: verktøyene, planleggingen, minnet, og kontekststyringen du instrumenterer modellen med. Som Harrison Chase skriver: det er denne selen som skiller en kapabel digital medarbeider fra en som faller av fjellveggen.

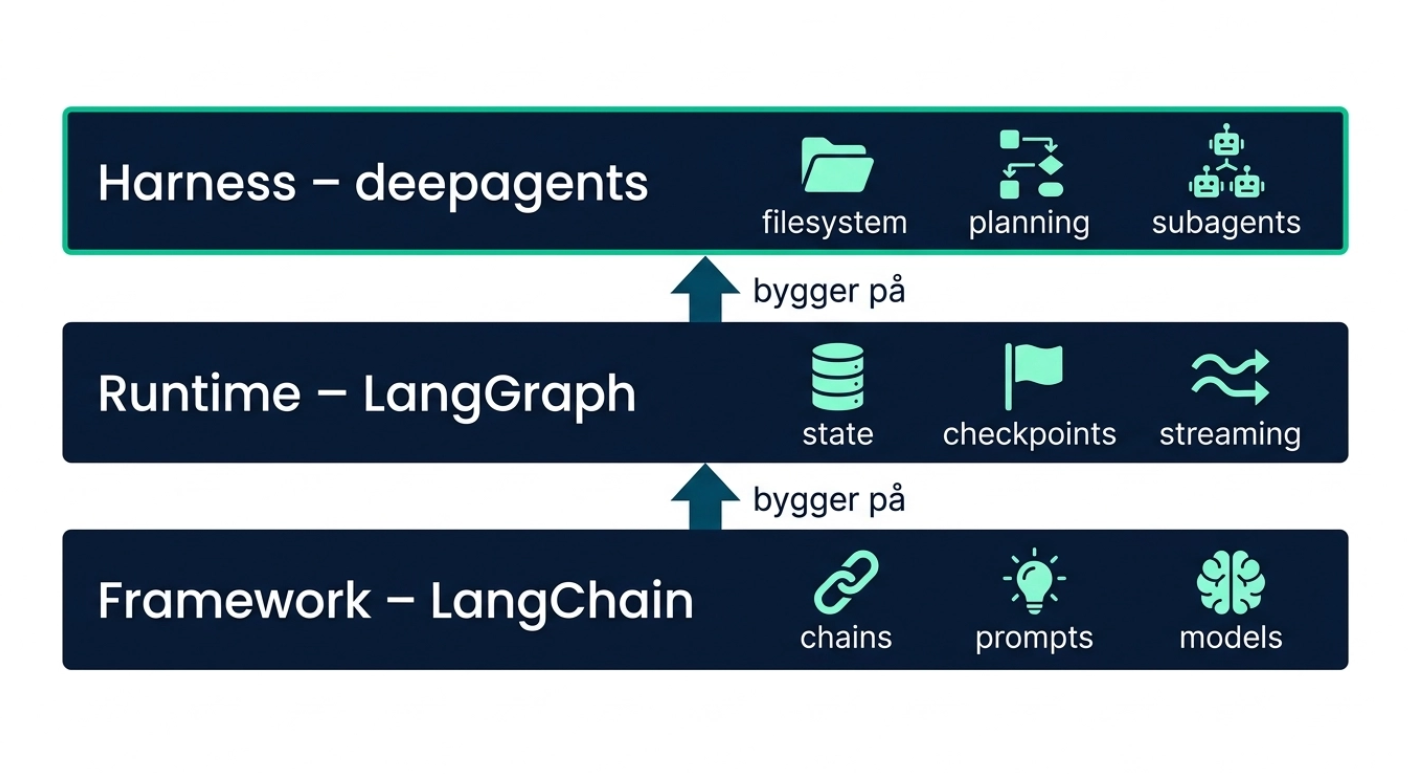
LangChain-økosystemet består av tre distinkte lag. Nederst har du LangChain som framework: abstraksjoner og en mental modell for å bygge med LLM-er. Over det ligger LangGraph som runtime: varig utførelse, streaming, persistens og human-in-the-loop. Øverst sitter deepagents som harness: alt fra de to lagene under, pluss forhåndskonfigurerte prompts, filsystem, planlegging og subagenter.
Et framework gir deg byggeklossene. En runtime gir deg infrastrukturen for produksjon. En harness tar deg fra null til fungerende agent med ett funksjonskall.
Når du oppretter en deep agent med create_deep_agent(), får du automatisk tilgang til et sett med kraftige verktøy, uten å måtte konfigurere noe selv.
Agenten har seks innebygde verktøy for filoperasjoner:
ls : List filer med metadata (størrelse, endringstid)read_file : Les innhold med linjenummer, støtter offset/limit for store filerwrite_file : Opprett nye fileredit_file : Utfør eksakte strengerstatningerglob : Finn filer som matcher mønstre (f.eks. **/*.py)grep : Søk i filinnhold med regex
Disse dekker de vanligste behovene, men du kan utvide med egne verktøy når domenet krever det.
Komplekse oppgaver krever en plan. Agenten kan bryte ned flerstegs problemer med det innebygde write_todos-verktøyet. Før den begynner arbeidet, skriver den ut en
oppgaveliste og oppdaterer statusen underveis:
# Agenten produserer automatisk en struktur som dette:
{
"todos": [
{"task": "Kartlegg API-mønstre", "status": "completed"},
{"task": "Implementer autentisering", "status": "in_progress"},
{"task": "Skriv tester", "status": "pending"}
]
}
Gjenkjenner du mønsteret? Det er det samme vi så i ReAct-løkken: tenk, planlegg, handle, observer, gjenta.
To mekanismer forhindrer at kontekstvinduet fylles opp. Dette er viktig, fordi en agent som mister oversikten over sin egen kontekst, mister evnen til å resonnere effektivt.
Utkasting av store verktøyresultater: Når et verktøyresultat overstiger 20 000 tokens, skrives det automatisk til en fil. Agenten får en referanse i stedet, og kan lese filen bit for bit ved behov. Se LangChain-bloggen om kontekststyring for detaljer om kompresjonsstrategiene.
Oppsummering av samtalehistorikk: Ved 170 000 tokens trigges en oppsummering. De siste 6 meldingene beholdes intakte, mens eldre meldinger komprimeres til et sammendrag.
Det største problemet med komplekse agenter er kontekstoverbelastning: når store verktøyresultater fyller opp kontekstvinduet og reduserer agentens evne til å resonnere.
Subagenter bidrar til å løse dette. Hovedagenten kan delegere en oppgave til en subagent som opererer med sin egen, isolerte kontekst. La oss se hvordan dette ser ut i kode:
from deepagents import create_deep_agent
research_subagent = {
"name": "research-agent",
"description": "Conducts in-depth research using web search",
"system_prompt": """You are a thorough researcher. Your job is to:
1. Break down the research question into searchable queries
2. Use internet_search to find relevant information
3. Synthesize findings into a concise summary
Keep your response under 500 words.""",
"tools": [internet_search],
}
agent = create_deep_agent(
model="claude-sonnet-4-5-20250929",
subagents=[research_subagent]
)
Subagenten utfører kanskje ti websøk, men hovedagenten mottar kun én oppsummering. Konteksten forblir ren.
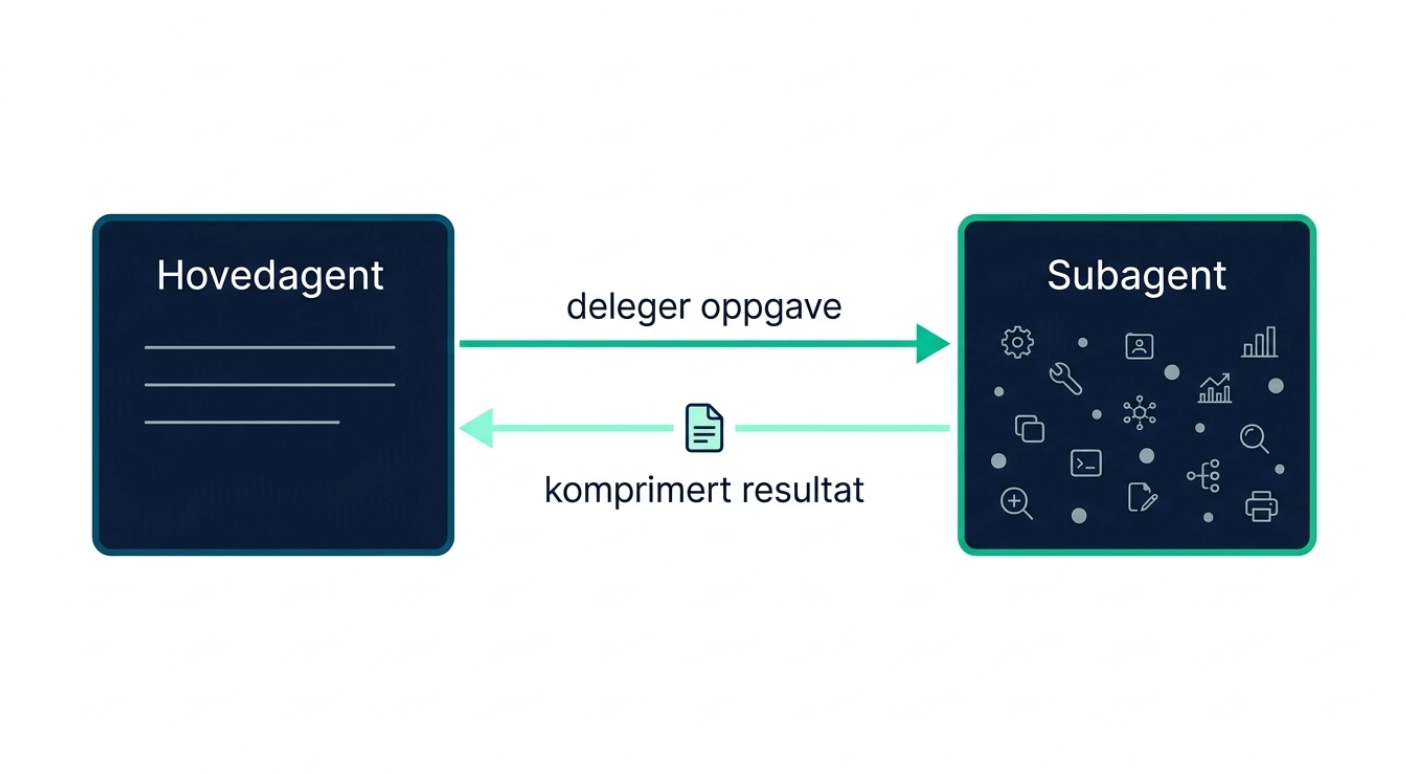
I tillegg til egendefinerte subagenter har du alltid tilgang til en general-purpose subagent. Den har samme instruksjoner og verktøy som hovedagenten, men opererer i isolert kontekst: perfekt for kontekstisolasjon uten spesialisert oppførsel.
Agentens filsystem er abstrakt og modulært, og du velger selv hvor filene faktisk lagres. StateBackend holder midlertidige filer innenfor én samtale og er ment å bruke kortsiktig (flyktig / "ephemeral"). FilesystemBackend gir ekte filtilgang på disk. StoreBackend bruker en database for langtidsminne på tvers av samtaler. Og CompositeBackend lar deg kombinere disse ved å rute ulike stier til ulike backends.
Den mest kraftfulle konfigurasjonen kombinerer flyktig og persistent lagring. Slik ser det ut i praksis:
from deepagents.backends import CompositeBackend, StateBackend, StoreBackend
from langgraph.store.memory import InMemoryStore
composite_backend = lambda rt: CompositeBackend(
default=StateBackend(rt), # Standard: flyktig (ephemeral)
routes={"/memories/": StoreBackend(rt)} # /memories/: persistent
)
agent = create_deep_agent(
backend=composite_backend,
store=InMemoryStore()
)
Med denne konfigurasjonen lever vanlige filer kun i samtalen, mens alt under /memories/ huskes på tvers av økter.
For sensitive operasjoner kan du konfigurere pauser før utførelse. Agenten stopper og lar deg godkjenne, redigere eller avvise operasjonen:
agent = create_deep_agent(
tools=[edit_file, deploy_code],
interrupt_on={
"edit_file": True, # Pause before every edit
"deploy_code": True # Pause before deploy
},
checkpointer=MemorySaver() # Required for HITL
)
Et mønster vi kjenner igjen fra LangGraph, men her ferdigkonfigurert og klart til bruk.
La meg dele en erfaring fra et klientprosjekt som illustrerer en viktig lekse.
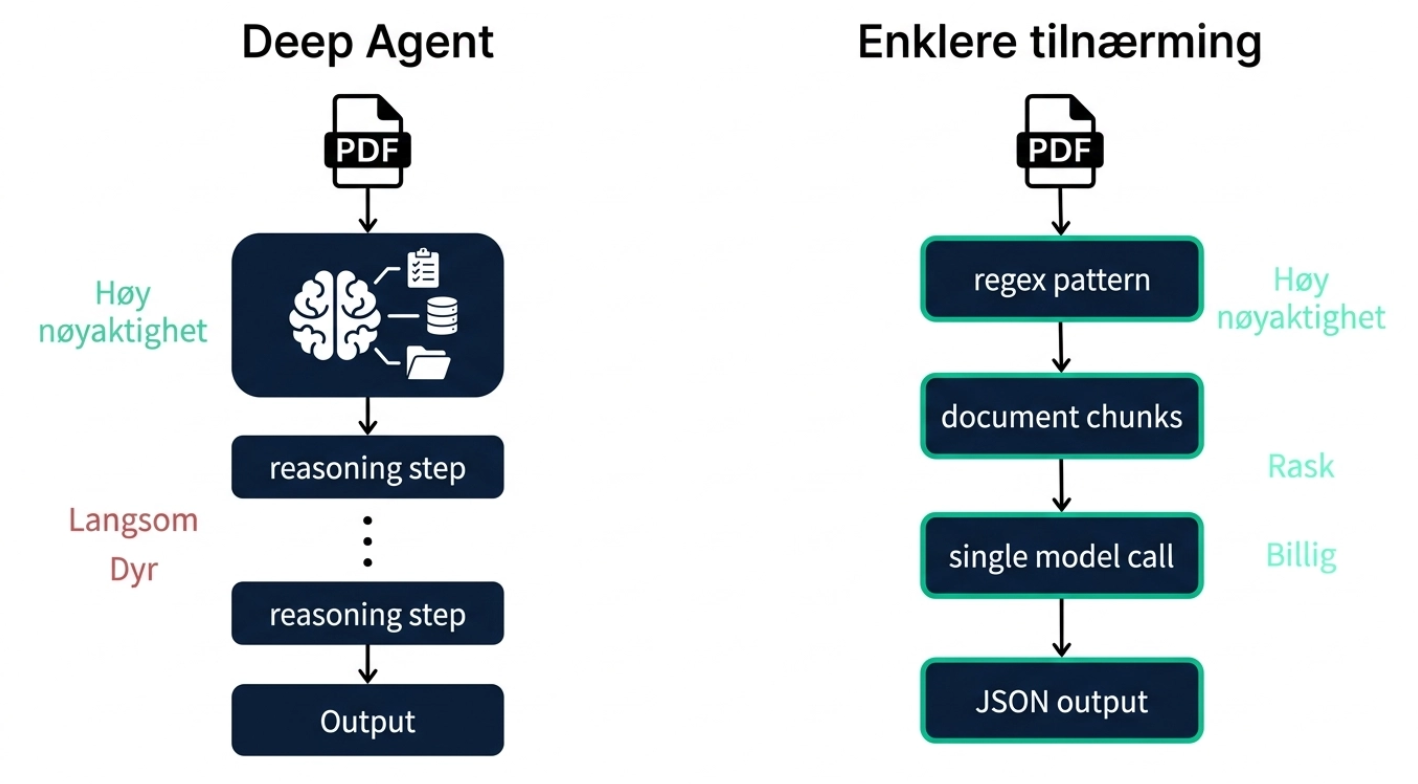
Vi bygde en uttrekkspipeline for PDF-dokumenter. Oppsettet var ambisiøst: PDF lastes opp, sendes til en deep agent som sporet oppgaver med write_todos, skrev til persistent minne for fremdrift, og tikket av mål etter mål. Nøyaktigheten var høy.
Agenten fungerte.
Men to ting ble raskt tydelige. For det første tok det altfor lang tid. Vi visste at uttrekket kunne gjøres raskere. For det andre var det dyrt: du betaler mange tokens for agentens resonnering i hvert steg, planleggingen, kontekststyringen, oppdatering av oppgavelisten.
Så vi skrev det om. I stedet for en fullverdig deep agent brukte vi regex-basert mønstergjenkjenning på tvers av dokument-chunks (ikke semantisk søk engang!), matet alt inn i en modell, og lot den produsere strukturert output. Resultatet var en raskere, billigere, og faktisk mer nøyaktig pipeline for den ustrukturerte dataen vi jobbet med.
Denne erfaringen lærte meg noe viktig. Det er fristende å kaste en kraftig sele og en kapabel modell på ethvert problem, i visshet om at den kan løse det. Men som Anthropic selv skriver: start enkelt, og legg til kompleksitet kun når det er nødvendig. En agent harness er et kraftig verktøy for oppgaver som krever flerstegs resonnering, planlegging og konteksthåndtering. For oppgaver som kan løses med et enkelt modellkall og god prompt-design, er den overkill.
Det handler ikke om å bevise at teknologien virker. Det handler om å velge riktig verktøy for jobben: hastighet, kostnad og nøyaktighet bør veie like tungt som kapabilitet.
Så nå kan du litt mer om deepagents-biblioteket, og kan evaluere om det er riktig verktøy for dine behov!
deepagents er LangChains offisielle agent harness: et bibliotek som pakker mønstrene fra hele denne bloggserien i én abstraksjon. Innebygd planlegging, filsystemverktøy, subagenter for kontekstisolasjon, fleksible lagringsbackends, og human-in-the-loop, alt ferdigkonfigurert.
Men den viktigste innsikten er kanskje denne: En god sele gjør ikke enhver klatring til rett klatring. Å vite når du trenger en fullverdig agent harness, og når et enkelt modellkall er nok, er det som skiller en god AI-utvikler fra en som bare kaster teknologi på problemet.
Ønsker du eller bedriften din å utforske hvordan AI-agenter kan styrke ansatte, prosesser eller applikasjoner? Ta gjerne kontakt med meg på LinkedIn. Vi i Capra har mange dyktige utviklere som jobber med nettopp dette.

Magnus bygger AI i Capra, nå på Gjensidiges «Hei, huset!». Han er opptatt av AI som fungerer i praksis og av å rigge tverrfaglige team for en AI-first arbeidsform. Det skriver han om og holder foredrag om.

.jpg)
