

Agenten vår hadde fungert godt i måneder. Systemprompten hadde dog vokst til over 200 linjer med instruksjoner for 12 ulike verktøy. Da vi la til en ny funksjon med sin egen flerstegsprosess, introduserte vi motstridende regler: én del av prompten sa "spør brukeren før du henter data," mens den nye delen sa "hent data før du spør." Agenten løste konflikten på sin egen måte og hoppet over halvparten av spørsmålene.

Vi oppdaget det ved å bruke agenten, ikke ved å kjøre evalueringer. Evalueringsoppsettet vårt var rett og slett ikke rigget for å fange denne typen feil. Det var en vekker: vi hadde investert hundrevis av timer i funksjonalitet, men nesten ingenting i å systematisk verifisere at helheten fortsatt hang sammen.
Tradisjonelle enhetstester fanger ikke denne typen feil. Agenter er ikke-deterministiske, og kvalitet er ofte subjektivt. Det betyr ikke at testing er umulig, men du trenger et nytt lag i teststrategien. I dette innlegget ser vi på hva det laget inneholder: testpyramiden for agenter, MLflow som case study for tracing og evaluering, og en CI-strategi som balanserer grundighet med kostnad.
Det finnes en testpyramide spesielt designet for AI-agenter som bygger på toppen av din eksisterende testinfrastruktur. Den har fire lag:
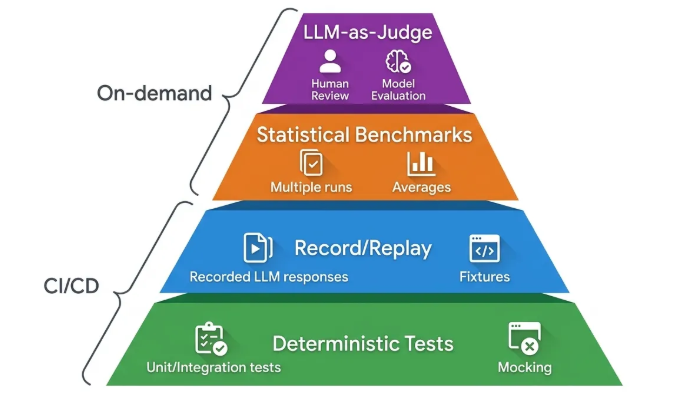
Lag 1: Deterministiske tester. Enhetstester med mock-providers. Rask, gratis, forutsigbare.
Lag 2: Record/replay. Forhånds-innspilte LLM-responser avspilles deterministisk i CI. Ekte agentoppførsel uten API-kostnader.
Lag 3: Statistiske benchmarks. Kjør testsettet flere ganger og mål gjennomsnitt. Mønstre over tid forteller mer enn kun én gjennomkjøring.
Lag 4: LLM-as-judge. En LLM evaluerer output fra en annen, med domene-spesifikke kriterier. Her hører også menneskelig vurdering hjemme.
Tradisjonelle tester (frontend, E2E, enhet, integrasjon) forsvinner ikke. Agentspesifikke evals er et tillegg, ikke en erstatning.
I praksis har vi til nå lagt mesteparten av innsatsen i lag 1. Det store flertallet av testene våre er deterministiske enhetstester som dekker forretningslogikk, API-kontrakter, verktøyskjemaer og databaseoperasjoner. Det er solid, og det fanger reelle feil. Men etter hvert som flere funksjoner lever i den agentiske chatten i tillegg til gjennom tradisjonell UI, treffer disse testene en stadig mindre del av det brukeren faktisk opplever. Vi har rigget et evalueringsoppsett med egendefinerte scorers og en CLI som kjører agenten mot kuraterte datasett og produksjonstracer i MLflow, men det kjøres fortsatt manuelt. Kombinert med opplevelsen fra innledningen, der vi ikke fanget motstridende promptinstruksjoner systematisk, peker det i én retning: evalueringsriggen må bli en del av CI-pipelinen, ikke noe vi sjekker når vi "føler" at noe er galt.
Flere verktøy dekker dette landskapet (LangSmith, Langfuse, Phoenix, DeepEval for å nevne noen), men jeg bruker MLflow (versjon 3.x) som eksempel her fordi det er det vi bruker i produksjon, er self-hostable, og fordi det kombinerer tracing, evaluering og eksperimentsporing i én plattform.
Med én linje fanger MLflow opp alle steg agenten tar:
import mlflow
mlflow.langchain.autolog(log_traces=True)
mlflow.config.enable_async_logging(True) # Non-blocking in production
Hvert verktøykall, LLM-invokasjon og retrieval-operasjon blir et span i et trace-tre:
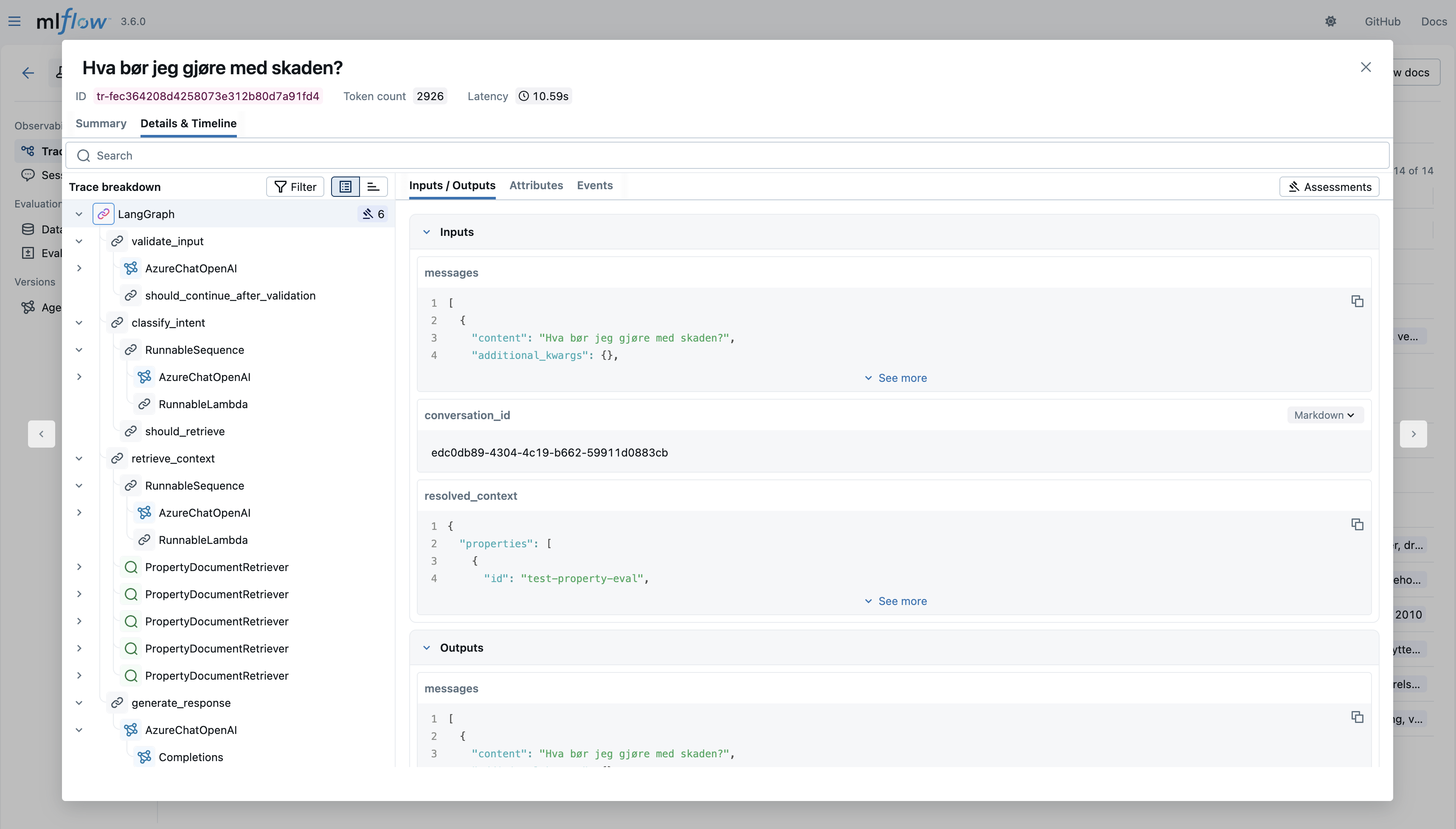
Første gang vi åpnet dette UIet etter å ha kjørt tester på produksjonsdata, var det flere ting som overrasket. For det første: den semantiske søkestrategien vår fungerte faktisk. Vi hadde designet en tilpasset retrieval-tilnærming, og tracene viste at den scoret høyt mot metrikkverdiene våre med ekte brukerdata. Det var en bekreftelse vi ikke hadde fått uten observabilitet.
Men den viktigste innsikten kom tidligere. Før vi gikk over til ReAct-mønsteret, hadde vi en egendefinert LangGraph-graf der vi manuelt definerte hvilke steg samtalen skulle ta basert på klassifisert intensjon. For eksempel: brukeren spør om taket, agenten klassifiserer det som "DOCUMENT_LOOKUP", og samtalen rutes til retrieval-noden. Problemet var at klassifiseringen ofte bommet. Et oppfølgingsspørsmål som "hva bør jeg gjøre med det?" ble klassifisert som "SMALLTALK" i stedet for å kobles til den pågående samtalen om taket. Tracene viste dette tydelig: vi kunne se nøyaktig hvor klassifiseringen feilet, og hvor ofte. Det var denne innsikten som formet beslutningen om å gå bort fra den egendefinerte grafen og over til ReAct-mønsteret vi bruker i dag. Uten tracing hadde den beslutningen vært basert på magefølelse og intuisjon, og ikke vært datadrevne.
MLflow 3.x har innebygde scorers for vanlige evalueringer (forankring (”groundedness”), relevans, sikkerhet), men den virkelige verdien ligger i å bygge dine egne for akkurat ditt domene:
from mlflow.genai.scorers import scorer
from mlflow.entities import Feedback
@scorer
def norwegian_language(*, inputs, outputs, **kwargs):
"""Check if agent responds in Norwegian."""
# Use a judge LLM with structured output
result = judge.invoke({"inputs": inputs, "outputs": outputs})
return Feedback(
value=1.0 if result.is_norwegian else 0.0,
rationale=result.explanation
)
Domene-spesifikke scorers er langt mer nyttige enn generiske metrikker. Vi bygde fire egne: GroundednessScorer (er svaret forankret i konteksten?), HelpfulnessScorer (adresserer svaret spørsmålet?), RetrievalRelevanceScorer (hentet RAG riktige dokumenter?), og NorwegianLanguageScorer (svarer agenten på norsk?).
En lærdom vi fikk tidlig var at ikke alle scorers kan brukes på alle responser. En forankring-scorer som evaluerer om svaret er basert på hentet kontekst vil gi false negatives på helt korrekte avvisninger fra assistenten som "Beklager, det kan jeg ikke hjelpe med." Svaret er riktig, men det finnes ingen kontekst å forankre det i. Løsningen var å la scoreren sjekke den klassifiserte intensjonen først, og returnere "ikke aktuelt" for kategorier der metrikken ikke gir mening, i stedet for å score den som feil.
Evaluering er ikke noe du gjør én gang. Hamel Husain, som blant annet ledet teamet bak CodeSearchNet (en forløper til GitHub Copilot) og har jobbet med evalueringsoppsett på tvers av 35+ AI-produkter, anbefaler at 60-80 % av utviklingstiden bør gå til feilanalyse og evaluering: gå gjennom tracer og forstå hvor agenten feiler.
Offline evaluering kjører agenten mot kuraterte datasett med kjente forventninger etter hver promptendring. Online evaluering scorer produksjonstrafikk asynkront ved å sample tracer og overvåke trender. Begge mater det Anthropic kaller eval-svinghjulet:

Vi har allerede sett verdien av dette i praksis. Ved å analysere produksjonstracer oppdaget vi hvilke temaer brukerne spør mest om, og like viktig: hva de forventer at agenten kan gjøre, men som den ikke støtter ennå. Mønsteret er gjenkjennelig: brukeren spør om et tema, får et svar, og følger opp med "kan du gjøre det for meg?" Når agenten ikke kan det, og det skjer i volum, har vi et tydelig signal om hva som bør prioriteres å støttes som neste funksjonalitet i agenten til produktet.
Tommel opp/ned fra brukere (a la hva som finnes i ChatGPT og Claude) er en naturlig del av denne kontinuerlige sløyfen, men den har en åpenbar begrensning: den avhenger av brukerens vilje til å gi tilbakemelding. Volumet varierer. Hvis samtaletrafikken er høy nok, kan du likevel trekke ut verdifulle signaler, enten det er positive bekreftelser, feilmeldinger, funksjonsønsker, eller hallusinasjoner. Poenget er å ha infrastrukturen på plass slik at signalene fanges opp, ikke forsvinner.
Skal du kjøre LLM-evals i CI? Ja, men hvor mye og hvor ofte avhenger av teamet ditt, budsjett, iterasjonshastighet, sikkerhetskrav, og om du jobber med et greenfield-prosjekt eller en moden kodebase. En lagdelt tilnærming som kan fungere:
Hver commit: Kodebaserte sjekker som prompt-snapshots, skjemavalidering og enhetstester. Gratis og deterministiske.
Hver PR: Record/replay-tester der forhåndsinnspilte LLM-responser avspilles deterministisk. Gratis etter opptak.
Hver natt, hver 3. dag, eller ukentlig: LLM-as-judge-evalueringer med domene-spesifikke scorers. Typisk $1-5 per kjøring.
On-demand: Menneskelig vurdering der en domeneekspert gjennomgår feiltilfeller.
Record/replay er et naturlig mellomsted mellom rene mocks (for enkle til å fange promptfeil) og ekte LLM-kall (for dyre og ustabile for CI). Men ingen av disse valgene er universelle. Det riktige oppsettet er det som gir ditt team nok tillit til å shippe, uten å bli en flaskehals.
Vår erfaring så langt: ekte LLM-kall i CI koster tokens og tar opp compute-ressurser for organisasjonen, og derfor har vi kjørt evalueringene manuelt hittil. Men over tid har vi erfart at manuell kjøring ikke skalerer. Det er for lett å la det gli, og da er du tilbake til å oppdage regresjoner ved at noen tilfeldigvis bruker agenten og merker at noe er galt. Record/replay og flere evalueringer av agenten vår i CI er neste eksperiment for oss. Uansett tilnærming er én ting sikkert: evalueringsriggen fortjener like mye kjærlighet som selve applikasjonen, og den må kjøres ofte nok til at du har reell tillit til at systemet ikke har blitt dårligere.
Agenter er ikke-deterministiske, men de er testbare. Nøkkelen er å akseptere at testing av agenter er probabilistisk, og bygge en strategi rundt det:
Testing av agenter handler ikke om å eliminere usikkerhet. Det handler om å håndtere den, systematisk og kostnadsbevisst.

Magnus bygger AI i Capra, nå på Gjensidiges «Hei, huset!». Han er opptatt av AI som fungerer i praksis og av å rigge tverrfaglige team for en AI-first arbeidsform. Det skriver han om og holder foredrag om.


.jpg)