

Du som har jobbet en del med autonome agenter – har du egentlig kontroll på sikkerheten?

En kollega stilte meg et ærlig spørsmål nylig: «Du som har jobbet en del med autonome agenter – har du egentlig kontroll på sikkerheten?»
Nei. Ikke godt nok. Og det gjelder nok de fleste av oss. Vi snakker varmt om økt produktivitet og enorme kontekstvinduer, men vi stiller sjelden det ubehagelige spørsmålet: Hva skjer når noen lurer agenten vår?
I dette innlegget ser vi på hvorfor agenter er sårbare, hva som kan gå galt – og hva du faktisk kan gjøre med det.
I tradisjonell nettverksarkitektur skiller vi strengt mellom control plane (kommandoer og beslutninger) og data plane (innholdet som prosesseres). I en LLM finnes ikke dette skillet.
Systemprompt, brukerinstruksjoner og eksternt innhold blandes sammen til én lang sekvens av tokens. Modellen har ingen innebygd mekanisme for å si: «Denne teksten er en instruksjon fra sjefen, mens denne teksten bare er data jeg fant på nettet.» Alt er bare kontekst for å forutsi neste ord.
Prompt injection oppstår fordi LLM-en ikke klarer å skille mellom instruksjoner fra deg og instruksjoner som ligger gjemt i dataen den leser.
Og det stopper ikke ved data. Selv det agenten behandler som instruksjoner – verktøydefinisjoner, MCP-konfigurasjoner, meldinger fra andre agenter – kan være kompromittert. Det er ikke bare upålitelig data som er problemet, men også potensielt upålitelige instruksjoner.

Det er en treffende parallell til Morris-ormen fra 1988: Tidlige datamaskiner var sårbare nettopp fordi instruksjoner og data delte samme minneområde. Det tok tiår å løse. AI-agenter har det samme problemet – bare i ny innpakning.
Simon Willison bruker en modell han kaller The Lethal Trifecta . Når tre egenskaper møtes, oppstår høy risiko:
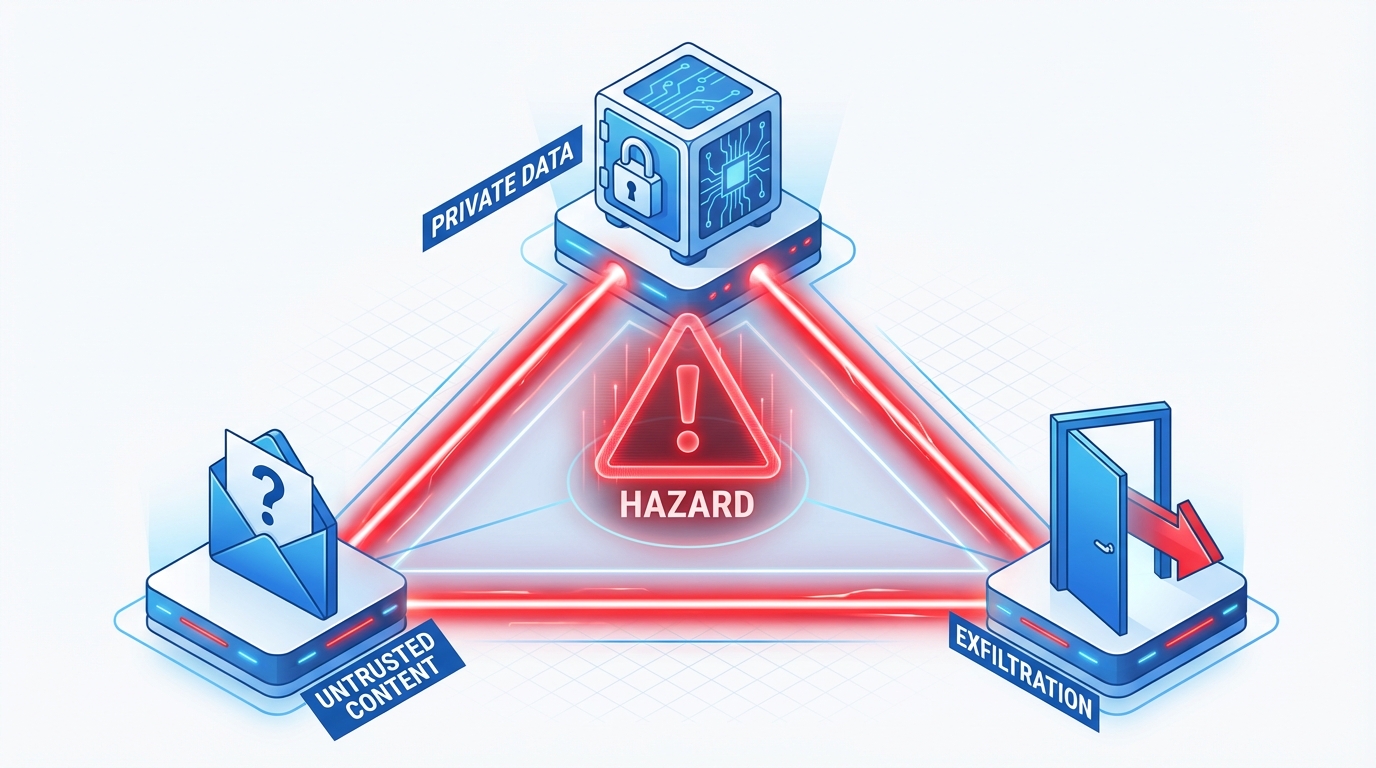
Her er det som kanskje er litt ubehagelig: Dette er standardoppsettet for de fleste nyttige agenter. Bruker du en kodeassistent med tilgang til terminalen, filsystemet og nettsøk? Da har du krysset av for alle tre.
Et forskerteam med folk fra OpenAI, Anthropic og Google DeepMind foreslo en «Rule of Two» : Agenter bør aldri ha mer enn to av disse tre egenskapene i samme sesjon. Det begrenser nytten, men det begrenser også risikoen betraktelig.
Sommeren 2025 ble en vekker. Sikkerhetsforskeren Johann Rehberger fant prompt injection-sårbarheter i nesten alle de store kodeassistentene – Cursor, GitHub Copilot, Google Jules, Amp Code og Devin AI. To eksempler som illustrerer alvoret:
Det holder at agenten leser én ondsinnet kodekommentar eller én kalenderinvitasjon for å potensielt kompromittere hele systemet.
Anthropic trener nå Claude med reinforcement learning der modellen eksponeres for prompt injection og belønnes for å avvise dem. Resultatet: Claude Opus 4.5 reduserte vellykkede angrep til 1,4 % i nettleserbaserte operasjoner – ned fra 10,8 % med tidligere forsvar.
1,4 % høres kanskje håndterbart ut. Det er det ikke.
Sannsynligheten for at en agent ikke blir kompromittert etter N interaksjoner med upålitelig innhold er 0,986^N. Etter 50 interaksjoner – en agent som besøker 50 nettsider i en sesjon – er sannsynligheten for minst ett vellykket angrep over 50 % . Etter 100: 75 %. I tradisjonell sikkerhet ville en tilgangskontroll som svikter 1 av 70 ganger bli klassifisert som en kritisk sårbarhet. 1,4 % per interaksjon er ikke en mur – det er en nedtelling.
Forskningsartikkelen "The Attacker Moves Second" (2025) bekrefter bildet: De testet 12 publiserte forsvar med adaptive angrep og brøt alle 12 med over 90 % suksessrate . OpenAIs leder for Preparedness sa det rett ut: «Prompt injection is unlikely to ever be fully 'solved'.»

Prompt injection får mest oppmerksomhet, men OWASP Top 10 for Agentic Applications 2026 dekker ti distinkte risikokategorier. Noen av de viktigste:
Minneforurensing. I motsetning til prompt injection, som ikke vedvarer utover én sesjon, kan en angriper forgifte en agents langtidsminne eller delte kontekst. Effekten vedvarer på tvers av sesjoner – agenten «lærer» feil ting permanent.
Verktøymisbruk og kodefeil. Agenter kan bruke verktøy feil uten at noen angriper dem. En kodeagent som genererer et script som ved et uhell sletter data, er ikke ondsinnet – men konsekvensen er den samme. Den probabilistiske naturen til LLM-er betyr at selv det «riktige» svaret kan variere fra gang til gang.
Forsyningskjedeangrep. Ondsinnet kode i MCP-servere, agentbiblioteker eller verktøydefinisjoner aktiveres ved kjøretid. Barracuda identifiserte 43 agent-rammeverkskomponenter med innebygde sårbarheter.
Cascading svikt i multi-agent-systemer. Én hallusinerende agent kan forgifte beslutningene til en hel pipeline. Uten isoleringsmekanismer sprer feilen seg ukontrollert – og det trenger ikke være et angrep. Det holder med en dårlig dag for modellen.
Du trenger ikke vente på at bransjen løser dette for deg. Her er konkrete tiltak:
Least Privilege. Gi agenten kun rettighetene den faktisk trenger. Claude Code har tillatelsesmoduser der du eksplisitt godkjenner hvilke verktøy som er tilgjengelige. Bruk det, selv om det kan oppleves veldig behagelig eller praktisk å skru på "bypass permissions" for å slippe å bekrefte hver handling.
Isolerte miljøer. Plattformer som E2B og Daytona tilbyr sandboxing via microVM-er. Alternativt: Docker-containere med snapshot og rollback.
Behandle agent-output som untrusted. Samme mentalitet som med brukerinput i webapplikasjoner. Validér, logg og krev bekreftelse for sensitive handlinger.
Hold agenter borte fra din e-post. OpenClaw-hendelsen i januar 2026 viste hva som skjer når tusenvis av agenter kjører med full tilgang til e-post og Slack uten autentisering. Hvis du først skal eksperimentere med OpenClaw eller liknende arbeidsflyter, gi agenten din egne innbokser i stedet .
Etter å ha gravd meg ned i dette temaet, har jeg blitt mer bevisst på hvilke verktøy jeg gir agentene mine tilgang til, og hvilke nettsider jeg lar dem søke gjennom. Det er en balansegang – for stramt, og du mister produktiviteten som gjør agenter verdifulle i utgangspunktet. For løst, og du inviterer inn risiko du ikke ser.
Agentverktøy senker terskelen enormt, og det er fantastisk – men det betyr også at folk som ennå ikke har internalisert sikkerhetstankegang, jobber med verktøy som potensielt har tilgang til alt.
Dette er ikke bare et arkitekturproblem man kan løse med bedre oppsett. Det er en fundamental egenskap ved hvordan språkmodeller fungerer – de skiller ikke mellom instruksjoner og data. Arkitekturen bestemmer hvor stor skaden kan bli, men sårbarheten ligger i selve modellen. Sandboxing, least privilege, forsvar i dybden – alt hjelper, men det er plaster på et problem som ennå ikke har en dypere løsning.
Ansvaret ligger hos oss som bygger med disse verktøyene – og det starter med å faktisk forstå hva vi eksponerer.

Magnus bygger AI i Capra, nå på Gjensidiges «Hei, huset!». Han er opptatt av AI som fungerer i praksis og av å rigge tverrfaglige team for en AI-first arbeidsform. Det skriver han om og holder foredrag om.

.jpg)
