

Det hele startet som et sideprosjekt én helg. Jeg ville bare se om det var mulig å få én brukerflyt til å kjøre gjennom automatisk - fra "opprett sak" til "fatt vedtak". Med Claude Code som AI-assistent fikk jeg det til å fungere, og plutselig hadde vi noe som faktisk var nyttig.

Melosys er NAVs system for håndtering av medlemskap i folketrygden og trygdeavgiftsberegning for personer som jobber på tvers av landegrenser. Systemet består av over 17 mikrotjenester, en Oracle-database, Kafka-meldingskøer og kompleks forretningslogikk. Ikke akkurat det enkleste systemet å E2E-teste.
Tre måneder og kanskje to ukers effektiv arbeidstid senere har vi 54 tester, et fullverdig CI/CD-oppsett med automatiske triggere, og har oppdaget 7 produksjonsfeil. Denne artikkelen tar deg med på reisen.
Målet var ambisiøst: automatisere komplekse brukerflyter fra "opprett sak" til "fatt vedtak" i et system med mange avhengigheter. Vi startet med det mest grunnleggende - å få alle tjenestene til å kjøre sammen.
Den største tekniske utfordringen var å få alle tjenestene til å snakke sammen. Melosys-økosystemet består av:
En kritisk designbeslutning var å bruke et eksternt Docker-nettverk som alle tjenestene kobler seg til. Dette gjør at tjenestene kan finne hverandre via interne DNS-navn, akkurat som i produksjon.
En av de viktigste delene av infrastrukturen er dispatch-systemet som automatisk kjører E2E-tester når noen pusher kode.
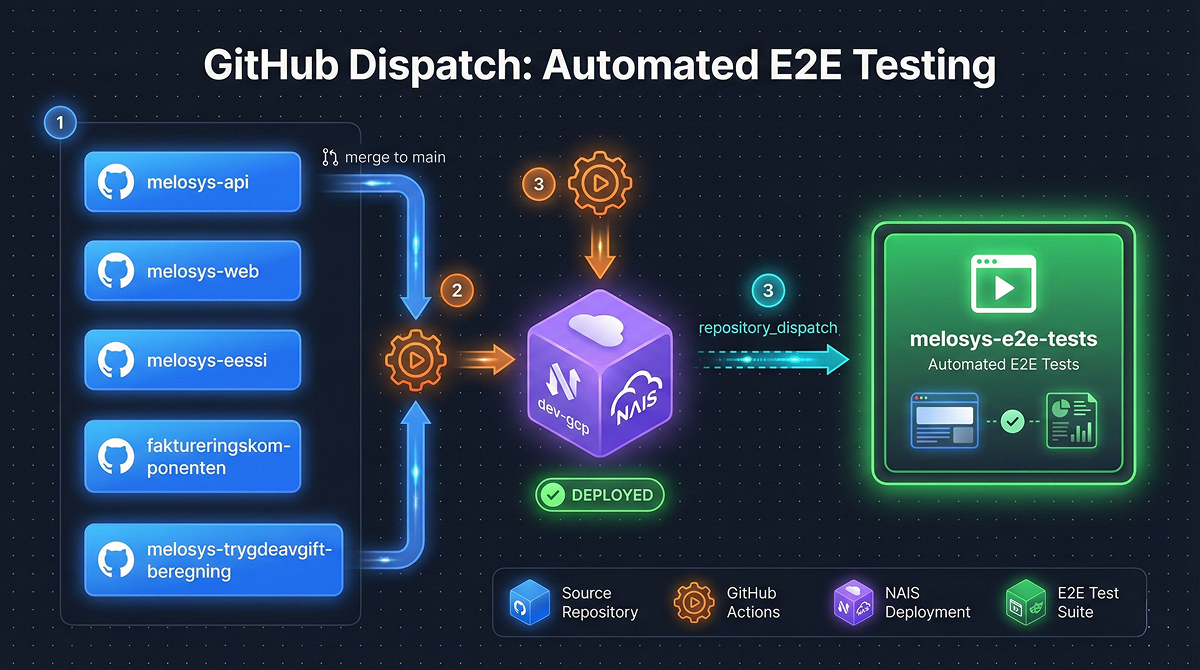
latestrepository_dispatch event til E2E-repoetEn viktig del av strategien vår er hvordan vi tagger Docker-images. Når kode merges til main, bygges en image og tagges som latest . Denne latest -tagen brukes i:
Dette betyr at utviklere lokalt kan kjøre nøyaktig de samme image-versjonene som kjører i test- og utviklingsmiljøene. Ingen "det fungerer på min maskin"-problemer.
I tillegg til automatiske triggere kan vi kjøre testene manuelt med flere nyttige parametere:
melosys-api:fix-bug,melosys-web:latest )Muligheten til å spesifisere ulike tags for ulike tjenester er kritisk for debugging. Hvis vi mistenker at en feil ligger i melosys-web, kan vi kjøre med melosys-web:fix-attempt-1 mens alle andre tjenester bruker latest .
Den virkelig spennende delen av prosjektet er hvordan vi bruker Claude Code til å automatisk debugge og fikse feil i systemet.
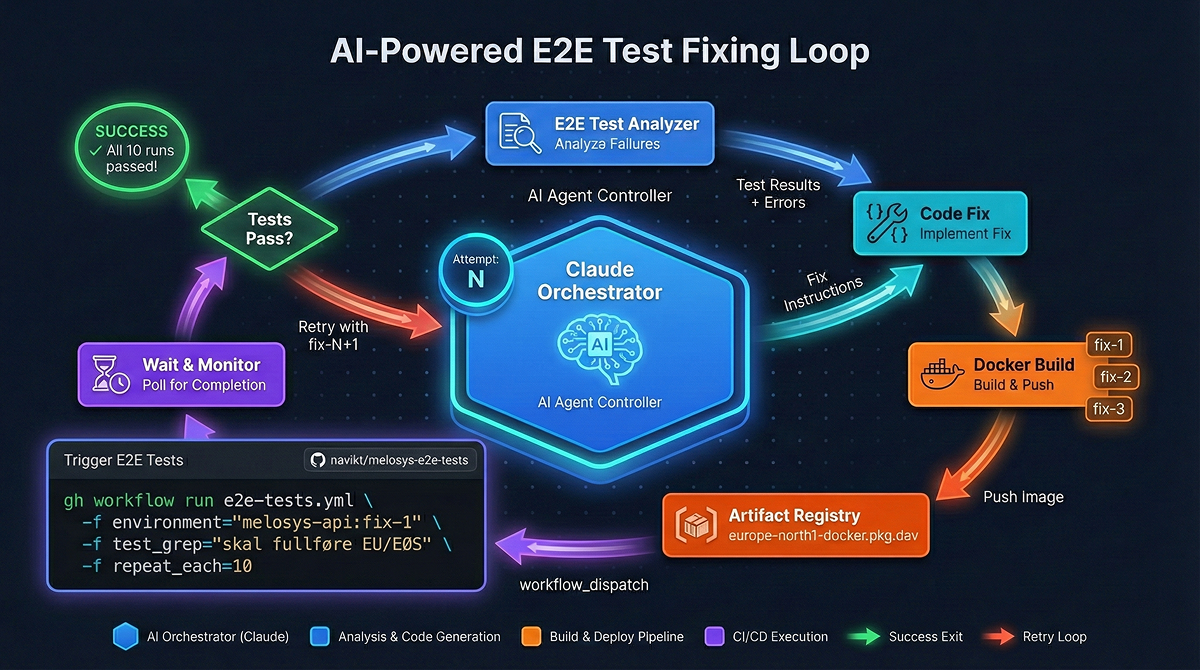
Når en E2E-test feiler i CI, kan Claude Code analysere feilen og forsøke å fikse den automatisk. Prosessen ser slik ut:
Claude Code har en egen skill ( gh-test-results ) som laster ned og analyserer testresultater fra GitHub Actions. Den henter:
Basert på analysen kan Claude Code identifisere om feilen ligger i:
Claude Code kan deretter navigere til riktig repository (melosys-api, melosys-web, osv.) og implementere en fix. Dette kan være alt fra å legge til en API-venting i frontend til å fikse en race condition i backend.
Med en annen skill ( docker-build-push ) bygger Claude Code en ny Docker-image lokalt og pusher den til GAR. Viktig her er at vi bruker en unik tag - ikke latest - slik at vi kan teste fixen uten å påvirke andre. For eksempel melosys-web:fix-arbeidsgiver-v1
Claude Code trigger en ny E2E-kjøring med:
melosys-web:fix-arbeidsgiver-v1 )latesttest_grep )repeat_each: 10 ) for å verifisere stabilitetHvis testen fortsatt feiler, analyserer Claude Code de nye resultatene og prøver en annen tilnærming. Den bygger en ny versjon ( fix-arbeidsgiver-v2 ), pusher, og tester igjen. Denne løkken kan fortsette til en stabil løsning er funnet.
Noen ganger krever en fix endringer i flere repositories samtidig. Kanskje frontend trenger en ny venting, og backend trenger å returnere data raskere. Da kan vi:
melosys-web:fix-timing-v1melosys-api:fix-timing-v1melosys-api:fix-timing-v1,melosys-web:fix-timing-v1Dette gir oss muligheten til å teste kombinasjoner av endringer på tvers av repositories før vi merger noe.
La oss si at EU/EØS-testen feiler sporadisk med en timeout på arbeidsgiver-valg. Claude Code vil:
melosys-web:fix-arbeidsgiver-v1environment=melosys-web:fix-arbeidsgiver-v1, test_grep=EU/EØS, repeat_each=10fix-arbeidsgiver-v2Denne iterative prosessen har dramatisk redusert tiden vi bruker på å debugge flaky tester.
En av de viktigste beslutningene for stabilitet var å kjøre testene sekvensielt med kun én worker. Hvorfor?
Oracle-databasen tar tid å starte opp. Uten eksplisitt venting ville testene starte før databasen var klar. I GitHub Actions venter vi på at alle kritiske tjenester er friske:
if [ "$oracle_health" = "healthy" ] &&
[ "$kafka_health" = "healthy" ] &&
[ "$api_health" = "healthy" ]; then
echo "✅ All critical services are healthy!"
fi
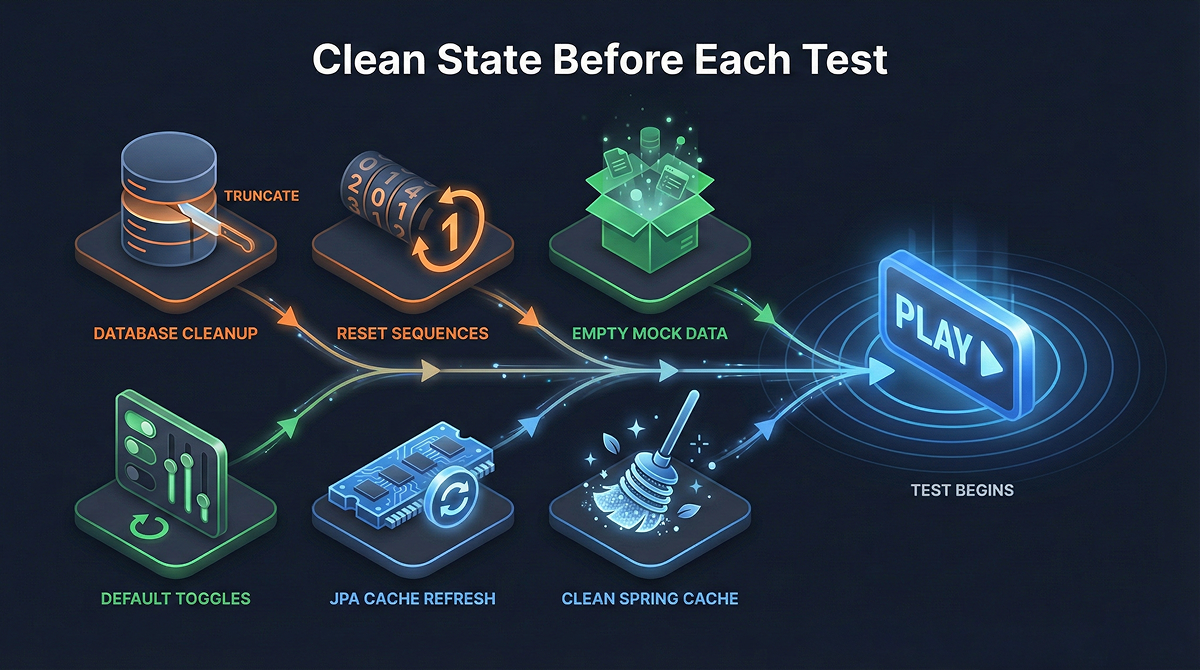
Hver test logger start- og sluttid. Etter testen sjekker vi Docker-loggene fra alle tjenester for feil som oppsto i det tidsvinduet. Feil kategoriseres som SQL-feil, connection-feil eller andre feil, og legges ved i testrapporten.
I starten brukte vi inline-selektorer direkte fra Playwright Codegen. Dette ble raskt uvedlikeholdbart. Vi migrerte til Page Object Model (POM) der hver side har sin egen klasse med metoder som fyllInnBrukerID() og velgSakstype() .
Testene ble mye mer lesbare. I stedet for kryptiske selektorer som getByRole('combobox', { name: 'Velg land' }) kan vi skrive behandling.velgLand('Danmark') .
Gjennom prosjektet møtte vi mange race conditions. Den mest komplekse var knyttet til saga-mønsteret i backend.
Melosys-api bruker et saga-mønster for å orkestrere flerstegsprosesser asynkront. Når en saksbehandler fatter et vedtak, starter en saga som går gjennom steg i en egen tråd - for eksempel å sende brev, oppdatere registre, og generere meldinger.
Problemet er at frontend og backend ikke er synkronisert. Frontend vet ikke at sagaen kjører, og sender mange parallelle API-kall mens backend er opptatt med å prosessere. Dette skaper konflikter - flere transaksjoner prøver å oppdatere samme data samtidig.
Dette er et symptom på at det var mer frontend-kompetanse enn backend-kompetanse da løsningen ble laget. Mye logikk ble lagt i frontend som egentlig burde vært i backend. E2E-testene avdekket dette mønsteret konsekvent, mens manuell testing bare sporadisk traff timingen.
Etter at vi fikk E2E-testene til å kjøre stabilt med Docker-loggmonitorering, oppdaget vi 7 produksjonsfeil som vi kunne fikse. Kombinasjonen av Playwright-traces og Docker-logger fra melosys-api ga oss innsikt vi aldri hadde fått ellers. Vi kunne se nøyaktig hva frontend gjorde, og samtidig hva som skjedde i backend - inkludert feil som bare logges og aldri vises til bruker.
Dynamiske dropdowns : Mange dropdowns lastes basert på tidligere valg. Hvis vi prøver å velge en verdi før listen er populert, feiler testen.
Feature toggle-propagering : Når vi endrer en toggle, tar det tid før melosys-api henter den nye verdien.
Asynkrone prosessinstanser : Vi bygde et eget endpoint i melosys-api som venter på at alle prosessinstanser er ferdige før cleanup.
Utviklingstiden på bare 2 uker hadde ikke vært mulig uten Claude Code. AI-en navigerte seg gjennom 17 tjenester, fant race conditions i Docker-logger, og itererte på fiks til de var stabile.
Testene våre dekker FTRL-saker, EU/EØS lovvalg, trygdeavtalesaker, journalføring, oppgavebehandling, søk, SED-mottak, klagebehandling og årsavregning.
Vi burde startet tidligere. Det er mye vanskeligere å sette opp E2E-tester sent i et prosjekt. Systemet har vokst, avhengighetene er mange, og race conditions har fått tid til å manifestere seg i produksjon.
Men hadde vi prøvd dette med Selenium for noen år siden, hadde det ikke fungert like bra. Playwright sin auto-wait, trace-viewer, og moderne arkitektur gjør en enorm forskjell. Kombinert med AI-assistert debugging blir det faktisk gjennomførbart å teste et system med 17 tjenester.
Claude Code var avgjørende for hele prosjektet:
Å bygge en stabil E2E-testinfrastruktur for et komplekst distribuert system er utfordrende, men absolutt oppnåelig. Nøkkelprinsippene er:
Med riktig infrastruktur, automatiske triggere og AI-assistert debugging kan E2E-tester være en verdifull del av utviklingsprosessen, ikke en kilde til frustrasjon.

Rune er teknisk arkitekt i Capra Consulting, på oppdrag for Team Melosys i NAV IT. Med bakgrunn fra 3D-spillmotorer og søkemotorteknologi jobber han nå med AI-agenter og hvordan skape mest mulig verdi med dem.

.jpg)
