

Velkommen til det første innlegget i bloggserien "The Agentic Stack". Hvert innlegg er designet som en 5-minutters lesning – perfekt til morgenkaffen eller pendlertoget. Kort nok til å fordøyes i én økt, dyp nok til å gi deg noe nytt å tenke på.

I denne serien skal vi utforske de dype arkitekturmønstrene som nå endrer hvordan vi bygger programvare med kunstig intelligens. Vi befinner oss i et kritisk skifte: Vi beveger oss bort fra å bare "snakke" med modeller, til å bygge systemer som faktisk utfører arbeid.
For de av dere som har jobbet med LLM-er siden de første dagene av ChatGPT, kan de første konseptene virke kjente, kanskje til og med grunnleggende. Jeg oppfordrer dere likevel til å henge med. Denne serien er designet for å bygge et felles vokabular og et fundament som vi senere skal bruke til å utforske mer avanserte temaer. Vi skal bevege oss fra de enkle interaksjonene til blant annet kompleks multi-agent orchestration, utforske long-running autonomous agents, og se på hvordan vi kan fortsette å lære med agentic AI - og masse mer!
Mange utviklere i dag sitter fast i en arbeidsflyt der AI fungerer som en glorifisert chatbot. Vi skriver en instruks, får et svar, og kopierer det manuelt inn i koden vår. Kanskje du allerede bruker agentisk chat i IDE-en din – Cursor, Copilot eller lignende – og kanskje du til og med har prøvd terminal-baserte agenter. Det er flott! Men potensialet strekker seg mye lenger enn det. Ved å bevege oss fra statiske system prompts til dynamiske agentiske arbeidsflyter, kan vi transformere AI fra en assistent til en kollega (eller flere kollegaer!) som forstår kontekst, tar beslutninger og utfører komplekse oppgaver autonomt. Dette endrer fundamentalt hvordan vi som utviklere opererer – og hva vårt ansvarsområde blir for å sikre høy kvalitet i kode og digitale produkter.
Denne serien handler ikke bare om hvordan du kan bruke AI i din egen utviklingshverdag. Vi skal også dekke produktutviklingsperspektivet: Hvordan bygger du produksjonsklare agentiske applikasjoner for kunder og sluttbrukere? Hvordan setter du dem trygt i produksjon? Og ikke minst – hvordan tester og evaluerer du systemer der oppførselen ikke lenger er deterministisk? Vi skal utforske verktøyvalg, arkitekturstrategier og de praktiske mønstrene som faktisk fungerer i virkeligheten.
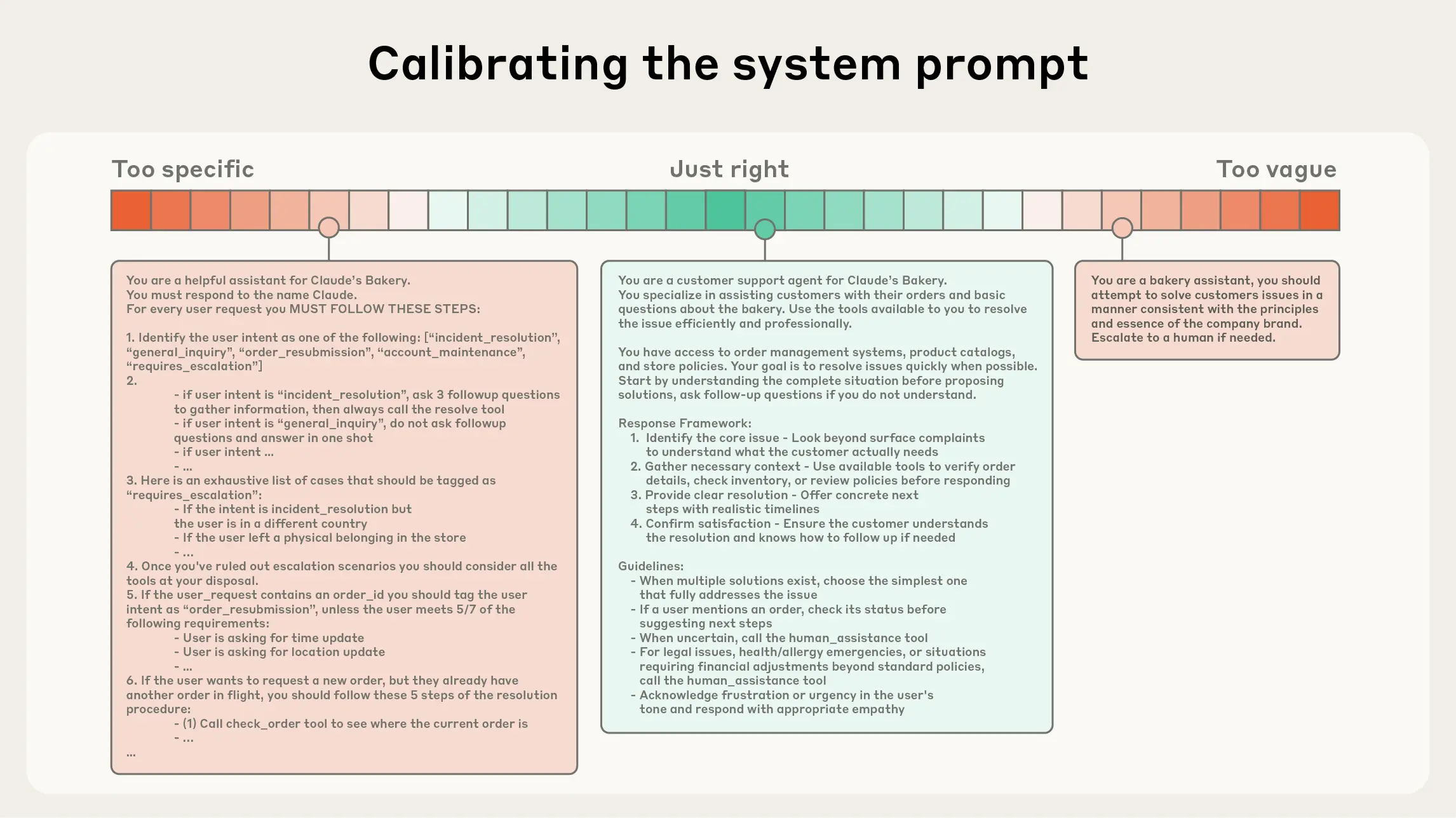
Vi lærte oss raskt verdien av en god system prompt. Dette er den permanente instruksen som setter rammer for modellens oppførsel, definerer dens personlighet og gir den retningslinjer for hvordan den skal svare.
En typisk system prompt kan fortelle modellen at den er en "dyktig seniorutvikler som prioriterer sikkerhet og lesbar kode".
Etter hvert som vi prøver å bygge mer komplekse applikasjoner, støter vi på en mur. En system prompt er i bunn og grunn statisk. Den er en del av den initiale konfigurasjonen, og selv om den kan være lang og detaljert, har den klare begrensninger. For det første er vi begrenset av modellens kontekstvindu. Jo mer vi pakker inn i en system prompt, jo færre tokens har vi til rådighet for faktisk problemløsning.
I tillegg mangler en tradisjonell prompt-basert tilnærming både tilstand (state) og kontrollflyt. Modellen har ingen innebygd evne til å huske hva den gjorde for tre steg siden uten at vi sender hele historikken tilbake, noe som fører til det vi kaller context rot – der viktig informasjon drukner i irrelevant støy. Uten tilgang til verktøykall forblir modellen innelåst i sitt eget tekstunivers.
Den kan foreslå hvordan du refaktorerer en funksjon, men den kan ikke selvstendig lese de relevante filene, gjøre endringene og verifisere at koden fortsatt fungerer. For å komme dit trenger vi noe mer enn bare bedre setningsoppbygging; vi trenger systemdesign.
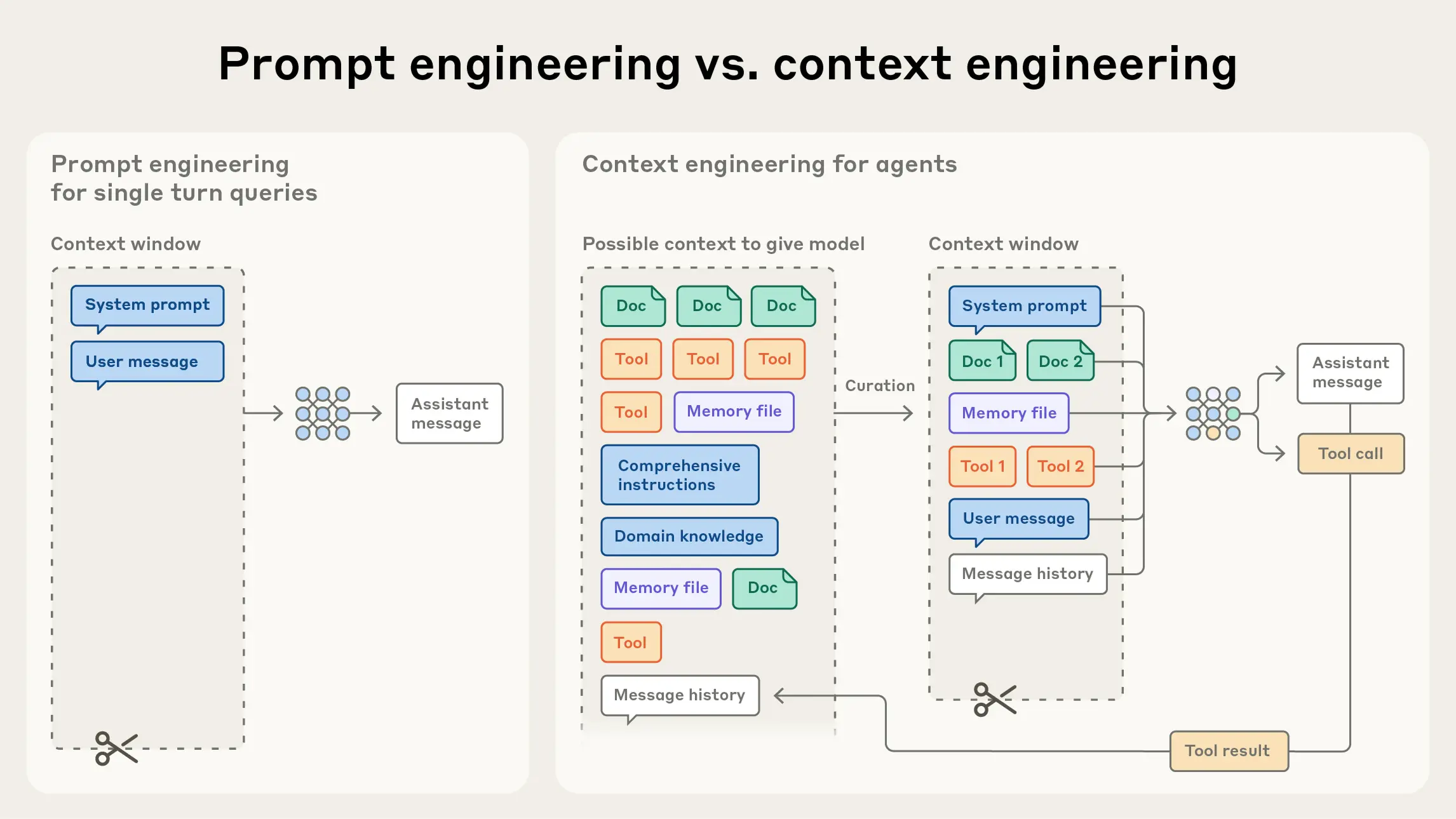
Det er her vi møter begrepet context engineering. Mens prompt engineering handler om hvordan vi skriver instruksjoner, handler context engineering om hvordan vi kuraterer og forvalter den totale informasjonsmengden som sendes til modellen ved hver inference. Dette er det naturlige neste steget i utviklingen.
Kjerneprinsippet i context engineering er å finne det minst mulige settet med high-signal tokens som maksimerer sannsynligheten for at modellen tar riktig beslutning. Det handler ikke om å dytte så mye informasjon som mulig inn i modellen, men om å være en nådeløs redaktør av agentens virkelighet.
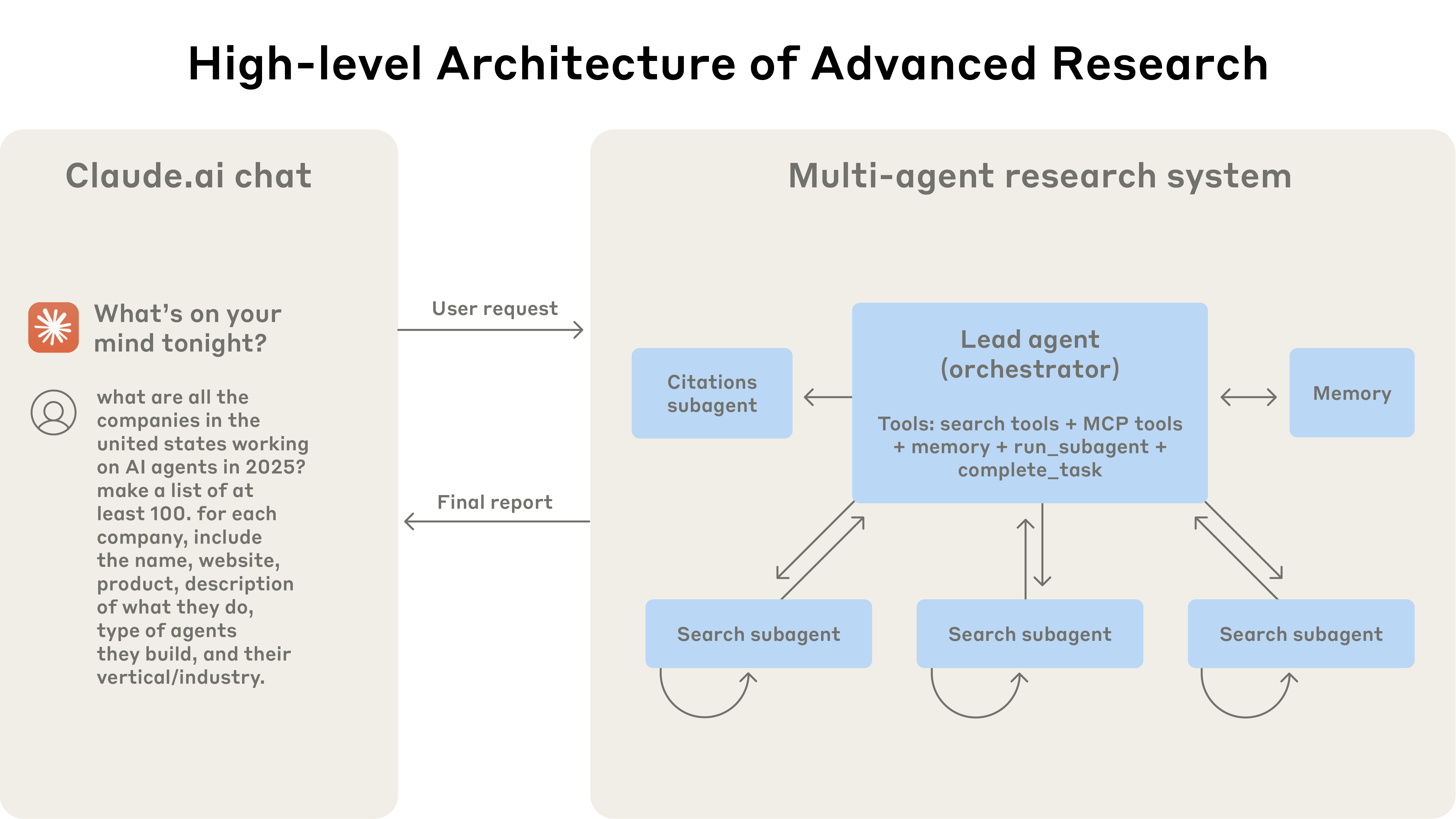
Når vi bygger agenter som skal operere over lengre tidshorisonter – såkalt long-horizon tasks – må vi ta i bruk mer avanserte strategier. Dette inkluderer teknikker som compaction, der vi kontinuerlig oppsummerer samtalen og reinitierer agenten med et destillert sammendrag når vi nærmer oss kontekstgrensen. Vi ser også fremveksten av sub-agent architectures, der en overordnet agent delegerer spesialiserte oppgaver til mindre agenter med rene, fokuserte kontekstvinduer. Dette forhindrer at modellen blir overveldet og sikrer at den alltid har den mest relevante informasjonen tilgjengelig for den spesifikke oppgaven den løser akkurat nå.
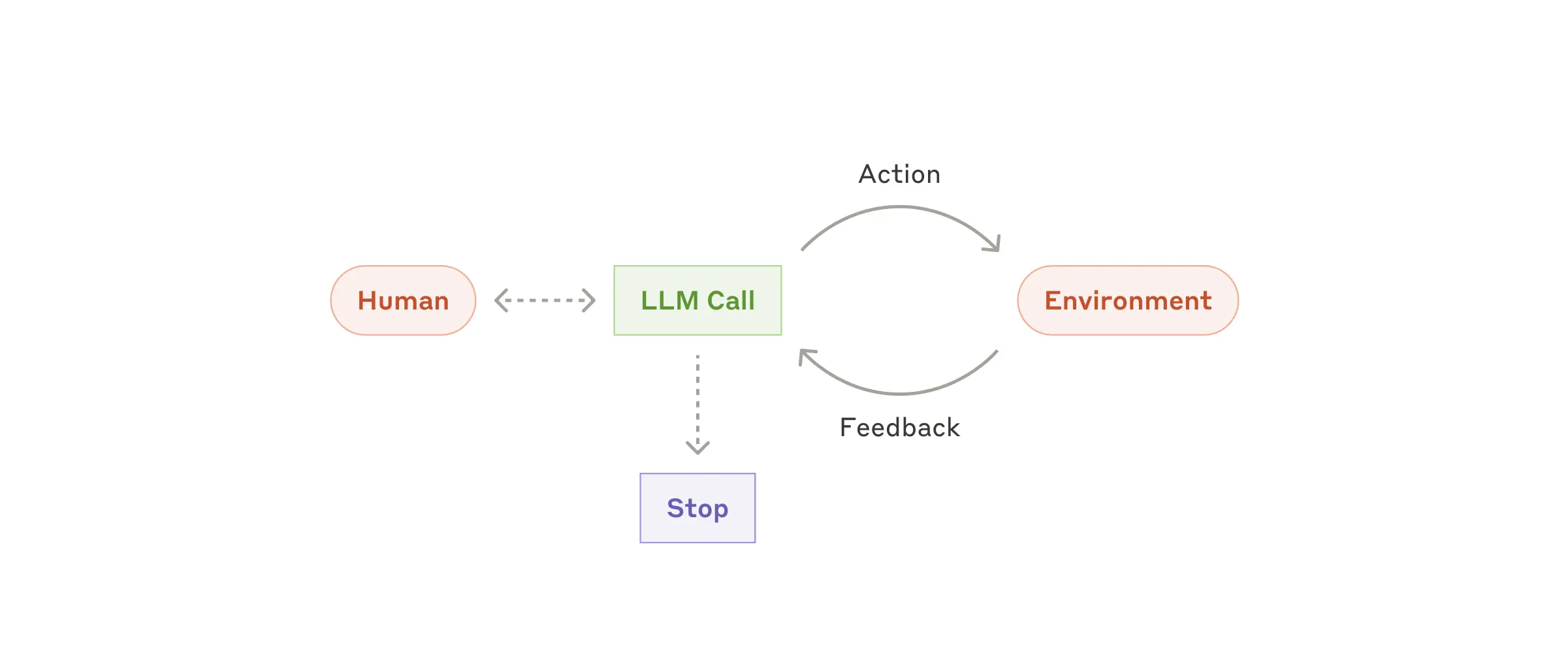
For å forstå hvordan en agent faktisk fungerer, trenger vi en mental modell som går utover lineær programmering. En av de mest effektive modellene er OODA loop, opprinnelig utviklet av militærstrategen John Boyd. OODA står for Observe, Orient, Decide, og Act.
For en AI-agent oversettes disse fasene direkte til tekniske operasjoner:
Denne syklusen gjentas helt til målet er nådd. Det som skiller en agent fra en enkel chatbot, er evnen til å navigere i denne sløyfen autonomt. Vi snakker ofte om fire pilarer som definerer en ekte agent:
Når hvert steg i "Act"-fasen gir ny informasjon som observeres i neste runde, ser vi disse pilarene i praksis.
Når vi ser på hvordan agenter faktisk implementeres i produksjon i dag, ser vi noen tydelige trender. En fersk studie viser at hele 70% bruker off-the-shelf modeller uten fine-tuning, og 79% fokuserer på manuell prompt-konstruksjon og context engineering. Dette understreker at måten vi rigger systemet rundt modellen på, ofte er viktigere enn selve modellen.
Et annet interessant funn er at de mest pålitelige systemene opererer med det vi kaller bounded autonomy, altså autonomi innenfor klare grenser. Rundt 68% av suksessrike agent-systemer utfører ti eller færre steg før de krever menneskelig intervensjon, såkalt human-in-the-loop (HITL). Dette er et viktig designprinsipp: Vi bygger ikke agenter for å erstatte oss fullstendig, men for å utføre fokuserte oppgaver der vi beholder kontrollen gjennom transparens og kontrollpunkter.
Arkitekturelt ser vi også at 85% av teamene velger å bygge sine egne rammeverk eller bruke lette biblioteker fremfor store, tunge abstraksjoner. Dette er fordi kontroll over kontrollflyten og tilstandshåndteringen er helt avgjørende for stabilitet. Det er også viktig å skille mellom agentiske arbeidsflyter og sanne agenter, en distinksjon Anthropic ofte trekker frem. Arbeidsflyter ("workflows") er systemer der LLM-er og verktøy orkestreres gjennom forhåndsdefinerte kodestier, ofte strukturert opp som en graf bestående av noder og kanter, noe som gir høy forutsigbarhet for veldefinerte oppgaver. Agenter, derimot, er bedre når fleksibilitet og modell-drevet beslutningstaking er nødvendig i stor skala. Valget mellom disse avhenger av balansen mellom behovet for kontroll og behovet for autonomi.
Vi har bare så vidt skrapt i overflaten av hva som er mulig når vi beveger oss fra statiske system prompts til dynamiske agentiske arbeidsflyter. Ved å forstå forskjellen på prompt engineering og context engineering, og ved å bruke modeller som OODA-loopen, kan vi begynne å designe systemer som er mer robuste, mer autonome og langt mer kapable.
Den viktigste lærdommen er kanskje denne: Fremtidens utvikling handler mindre om å skrive den perfekte instruksen, og mer om å designe det perfekte økosystemet for agenten å operere i - selvfølgelig innenfor trygge rammer.
I neste innlegg skal vi se nærmere på MCP – Model Context Protocol. Dette er den nye standarden som kobler våre agenter til lokale data og verktøy, og det er en essensiell brikke i den moderne agentiske teknologistakken.

Magnus bygger AI i Capra, nå på Gjensidiges «Hei, huset!». Han er opptatt av AI som fungerer i praksis og av å rigge tverrfaglige team for en AI-first arbeidsform. Det skriver han om og holder foredrag om.

.jpg)
