

Spol tilbake til august 2025. Det var da jeg hadde mitt "oh shit"-øyeblikk med agentisk koding.
.png)
Frem til da hadde jeg hovedsakelig brukt Agentic Chat i Cursor med Claude Sonnet. Det fungerte greit for isolerte oppgaver, men jeg traff stadig veggen på store nye features. I august 2025 var flaggskipmodellen til Anthropic Claude Opus 4.1. Den hadde potensial, men den trengte mye veiledning.
Så jeg begynte å utforske Plan Mode i Claude Code. Ideen om Plan Mode er enkel: la agenten analysere kodebasen og lage en plan før den begynte å kode. Men det som overrasket meg var ikke Plan Mode i seg selv. Det var hva som skjedde når jeg ga agenten en skikkelig gjennomtenkt spesifikasjon i stedet for en vag instruksjon.
Plutselig gikk outputen fra "nesten riktig, men treffer ikke helt" til "dette er nøyaktig det jeg mente - jeg og agenten er jo helt enige".
Det var starten på en arbeidsmetode som nå har et navn: Spec-Driven Development.
Spec-Driven Development (SDD) har ennå ikke én universelt akseptert definisjon, men det handler om å skrive en strukturert spesifikasjon før du ber agenten skrive kode. Specen blir kontrakten mellom deg og AI-agenten.
Birgitta Böckeler fra Thoughtworks definerer en spec som:
"A structured, behavior-oriented artifact, written in natural language that expresses software functionality and serves as guidance to AI coding agents."
Og SDD som praksis: å skrive denne specen før du skriver kode med AI ("documentation first"). Specen blir kilden til sannhet for både mennesket og agenten.
Addy Osmani utdyper dette ved å understreke at LLM-er ikke leser tankene dine. De trenger strukturert, eksplisitt kontekst. En god spec eliminerer tvetydigheten som fører til at agenten gjetter, og gjetter feil.
Det viktige å forstå er at SDD er en arbeidsmetode, ikke et verktøy. Uansett hvilken IDE du bruker, uansett hvilken kode-agent eller modell du foretrekker, kan du jobbe på denne måten: spec først, deretter implementering. Det handler om å gjøre tekniske beslutninger eksplisitte, reviderbare og klare for utvikling før en eneste linje kode blir skrevet.
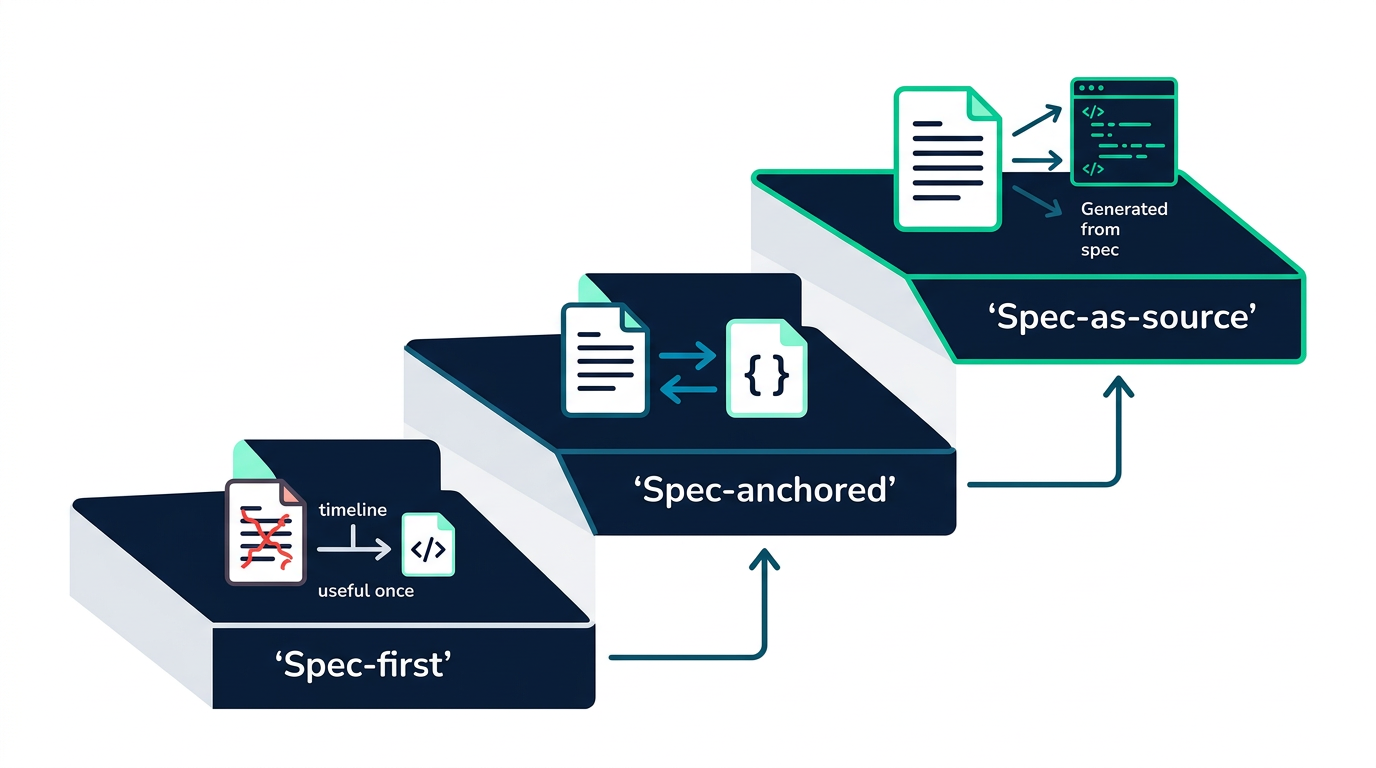
Böckeler identifiserer tre nivåer:
For de fleste team er spec-first et naturlig startpunkt, mens spec-anchored gir størst verdi for komplekse features. Spec-as-source er fortsatt noe eksperimentelt, men jeg legger stadig merke til flere og flere utviklere som avlaster mye av kodeskriving til dagens flaggskipmodeller og bruker mesteparten av tiden på å specce opp endringene som skal gjøres.
La meg være ærlig om hvordan forholdet mitt til specs har utviklet seg.
Da jeg startet med SDD i august 2025, var det tungt. Jeg brukte Plan Mode i Claude Code og skrev feature-specs med deloppgaver som jeg eksplisitt ba agenten huke av etterhvert som det fullførte hver oppgave. For større features opplevde jeg det ofte som vanskelig å håndtere. Det var mye kontekst, og modellene på det tidspunktet var ikke gode nok til å holde oversikten over alt.
Men så skjedde noe. Modellene ble dramatisk bedre. Med modeller som Claude Opus 4.6 og verktøy som Codex og Claude Code, merket jeg at forholdet mitt til specen endret seg. Det ble ikke mindre viktig. Tvert imot, det ble så innarbeidet i måten jeg jobber på at jeg nesten ikke tenker over det lenger.
Forskjellen er i hvor jeg bruker tiden min. Før var det mye mer hands-on med koden i hver fase. Nå bruker jeg mesteparten av tiden på å spesifisere featuren og tenke som en orkestrator: hva er alle de bevegelige delene i systemet? Hvilke filer er involvert? Hvilke constraints gjelder?
Deretter lar jeg agenten utforske kodebasen for å gjøre seg kjent. Jeg ber den stille meg oppfølgingsspørsmål. Ofte kan jeg bare si "utforsk mer kode," og den svarer på sine egne spørsmål. Andre ganger, hvis spørsmålet handler om arkitektur eller produktretning, bryter jeg inn. Men den initielle investeringen i en god spec betyr at agenten trenger færre runder med korrigering.
Andrej Karpathy kalte den ustrukturerte tilnærmingen "vibe coding" i februar 2025. SDD er det motsatte: presisjon først, deretter autonomi. Men du må ha hodet med hele veien, og sørge for å ikke bli agenten sin "yes man".
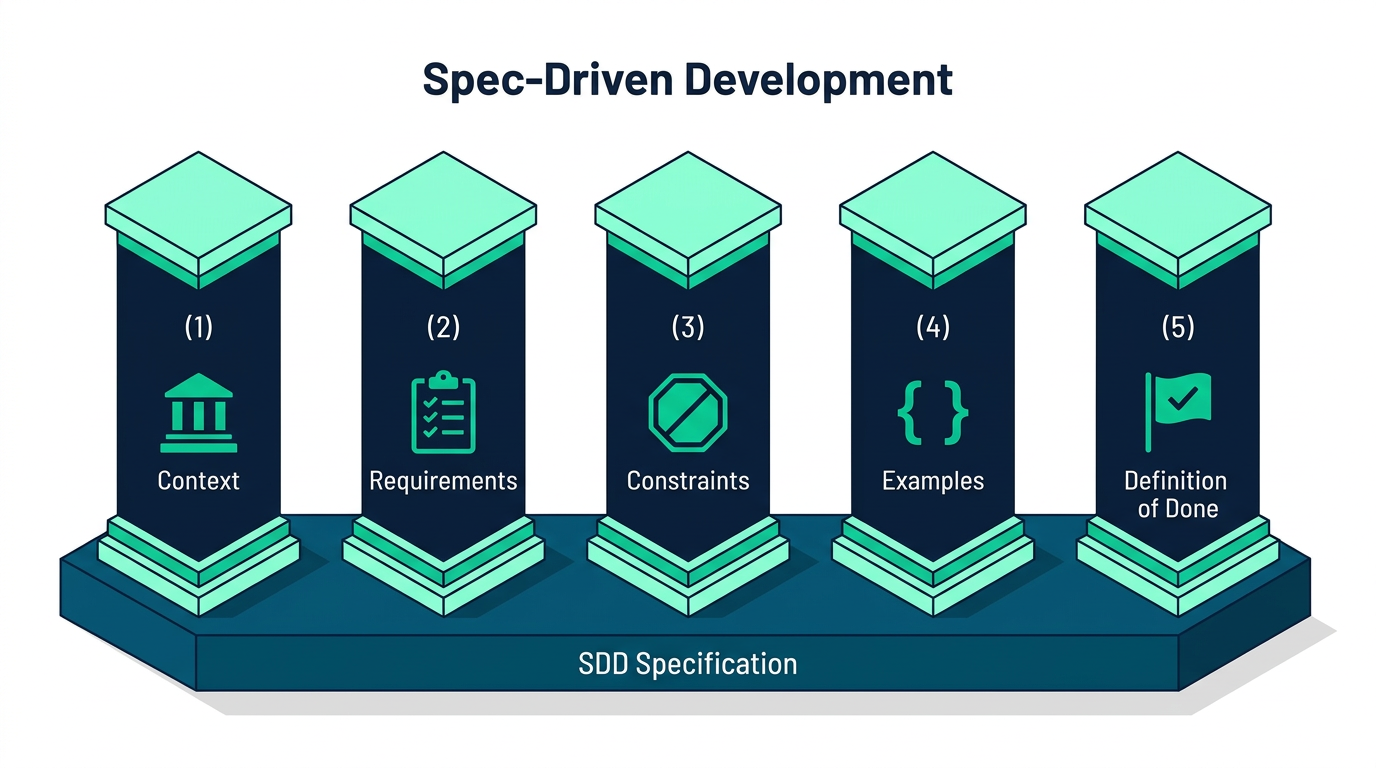
En god SDD-spesifikasjon bygger på fem pilarer:
La oss se forskjellen i praksis.
Migrer backend-servicene våre til Bun.
Agenten må gjette på alt: hvilke services, hvilken rekkefølge, hva med Docker, hva med kompatibilitet, hva med avhengigheter. Du ender opp med tre runder klargjøring før noe nyttig skjer.
## Feature: Migrate to Bun runtime and Bun workspaces
### Context
- Monorepo with 8 Docker-based services and 1 Next.js webapp
- Current stack: Node.js + npm with manual tsc compilation
- All services use 3-layer Docker builds (npm install → tsc → npm prune)
### Problem
Docker builds are unnecessarily complex, slow, and there is no
monorepo coordination between services.
### Requirements
1. Set up Bun workspaces in root package
- Workspaces: `web/`, `packages/*`, `docker/*`
2. Simplify Dockerfiles to `oven/bun:1-alpine`
- Remove tsc compilation, dist/, and prune steps
3. Migrate entrypoints to `bun run src/...`
4. Keep `web/` on Node.js (Next.js compatibility)
### Migration Order (lowest risk first)
1. fx-rates (simplest, no external dependencies)
2. api-gateway
3. notification-service
4. ...
5. website-scraper (highest risk: V8 memory flags)
### Constraints
- Do NOT migrate web/ to Bun (Next.js 15 lacks full support)
- Keep existing CI/CD pipeline structure
- Verify that pg SSL support works in Bun
### Definition of Done
- [ ] Bun workspaces configured and working
- [ ] All 8 services running on Bun runtime
- [ ] Docker image size reduced by ≥30%
- [ ] All existing tests pass
- [ ] web/ still on Node.js without regressions
Forskjellen er tydelig. Agenten vet nøyaktig hva den skal gjøre, i hvilken rekkefølge, og hva den ikke skal røre. Migrasjonsrekkefølgen betyr at den begynner med lavest risiko og bygger opp trygghet før den tar de vanskelige casene.
Her kommer innsikten som virkelig endret hvordan jeg jobber med SDD i team.
Det første man tenker er kanskje å legge specen i en Markdown-fil i kodebasen og versjonskontrollere den. Det fungerer for enkeltutviklere, men det skalerer dårlig. Filen er ikke delbar på en naturlig måte, den mangler diskusjonshistorikk, og den passer ikke inn i sprint-planlegging.
Løsningen er å bruke ditt team sitt prosjektstyringsverktøy som persistent hjem for specs. Jeg bruker GitHub Issues med GitHub CLI, men det samme prinsippet gjelder med Jira CLI, Linear, Notion MCP, eller hva teamet ditt allerede bruker.
Flyten ser slik ut:
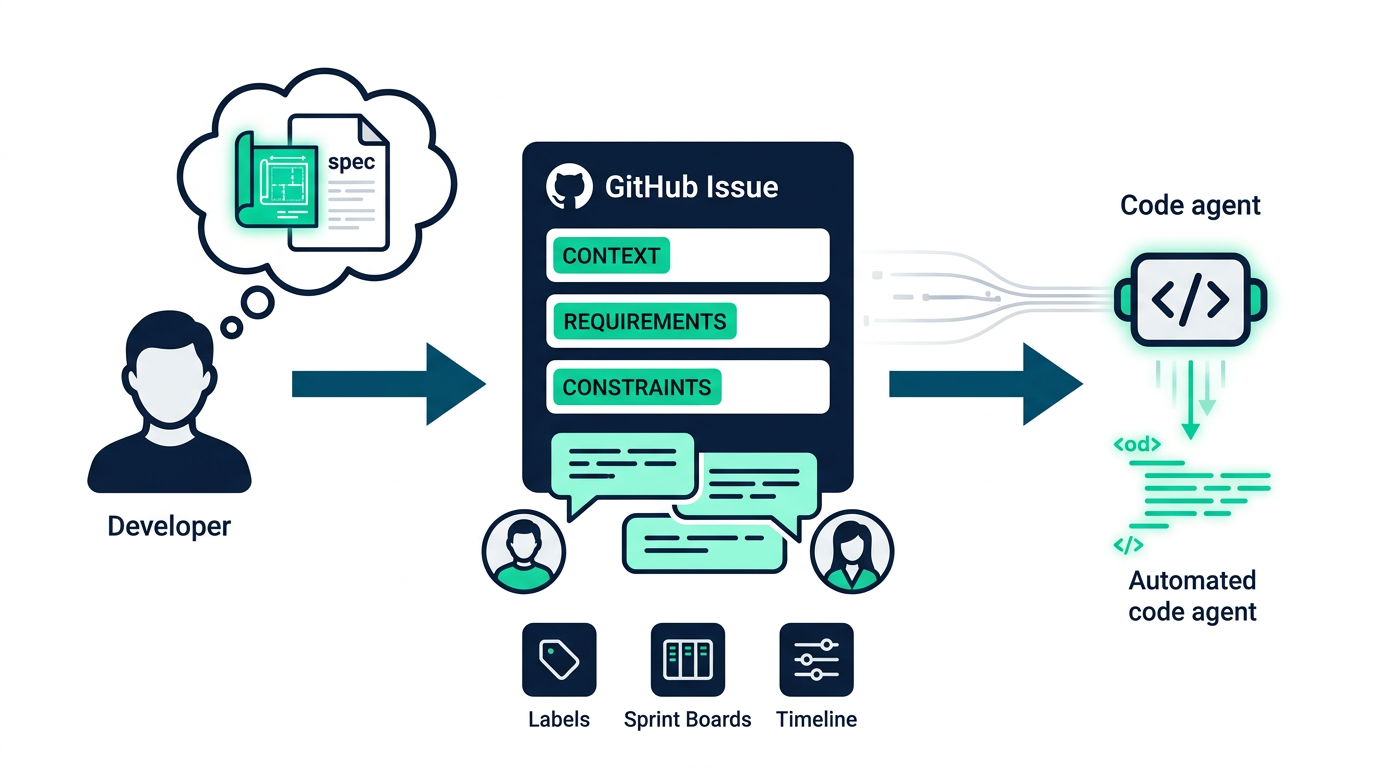
Tenk på issuet som din konseptuelle Plan Mode. Du har allerede gjort forarbeidet: identifisert filer, definert constraints, bestemt migrasjonsrekkefølge. Issuet kan leve der så lenge du trenger. Du kan merke det, legge det inn i sprint-planlegging, og engasjere ulike interessenter.
Når du så åpner kode-agenten din og peker den til issuet, trenger den ikke å gjøre seg kjent med kodebasen på nytt. Den har allerede blitt fortalt hvor den skal se, fordi du gjorde den jobben i spec-fasen.
Dette løser også et skalerbarhetsproblem. SDD er ikke bare for deg som enkeltutvikler. Når specen lever i prosjektstyringsverktøyet, kan hvem som helst på teamet plukke opp issuet og starte arbeidet. En kollega kan ta en av deloppgavene. En annen kan kommentere at constraint X er utdatert. Specen blir en felles kontrakt, ikke bare din private huskelapp.
Og når agenten har tilgang til prosjektstyringsverktøyet via CLI (f.eks. gh for GitHub), åpner det seg enda mer: branching, PR-oppretting, code review, og adressering av feedback kan alle bygges på toppen av specen som allerede ligger der. I teamet mitt har vi erfart at dette fungerer spesielt godt fordi alle kan se planen, og hvert steg i livssyklusen kan automatiseres inkrementelt. Men akkurat det er egentlig en egen post i seg selv.
Böckeler tar opp noen viktige bekymringer som er verdt å adressere:
"Er ikke dette bare vannfallsmodellen med AI?"
Ja, hvis du insisterer på å skrive hele specen ferdig før du begynner. I praksis bør det være en kontinuerlig prosess. Start med en grov spec, la agenten utforske og stille spørsmål, og oppdater specen underveis. Den iterative naturen gjør det mer likt agil utvikling enn vannfall.
"Det blir for mye Markdown å reviewe."
Berettiget bekymring. Sørg for å holde specs konsise og fokusert. De fem pilarene hjelper deg å skrive akkurat nok, ikke mer. Med det sagt vil jeg heller lese planen for å forstå intensjon og hvorvidt en annen utvikler har tenkt gjennom edge cases, enn å få servert en masse kode som ikke er tilstrekkelig dokumentert.
"Agenten følger ikke instruksjonene uansett."
Böckeler observerer at agenter "frequently don't follow all the instructions, even with multiple files, templates, and checklists." Det stemmer. Men en god spec gjør det enklere å oppdage avvik. Når du har en Definition of Done med sjekkbare kriterier, er det tydelig når agenten har bommet. Uten spec har du ingen referanse å sammenligne mot.
Spec-Driven Development handler ikke om mer dokumentasjon. Det handler om bedre kommunikasjon med AI-agenter.
Det som startet som en nødvendighet i august 2025 (fordi modellene trengte mer veiledning) har blitt en arbeidsmetode som gir verdi selv med dagens langt mer kapable modeller. Ikke fordi agentene alltid trenger å bli holdt i hånden, men fordi en god spec tvinger deg til å tenke gjennom problemet ordentlig før du setter agenten i arbeid.
De fem pilarene (Context, Requirements, Constraints, Examples og Definition of Done) gir deg et rammeverk som fungerer uansett verktøy. Og ved å bruke prosjektstyringsverktøyet som persistent hjem for specen, får du en arbeidsflyt som skalerer fra enkeltutvikler til helt team.

Magnus bygger AI i Capra, nå på Gjensidiges «Hei, huset!». Han er opptatt av AI som fungerer i praksis og av å rigge tverrfaglige team for en AI-first arbeidsform. Det skriver han om og holder foredrag om.


